 BipEx: Bipolar Exomes
BipEx: Bipolar ExomesQuality control pipeline
On this page we detail the quality control (QC) pipeline for for the BipEx dataset. Further plots, the underlying code and a document summarising the pipeline can be found on the BipEx github repository.
We first summarise the collection of samples, splitting across cohorts and subtypes. In addtition to Bipolar cases, we also a collection of Schizophrenia cases that will serve as positive controls for our PTV burden analyses.
| Location | Bipolar Disorder | Schizoaffective | Schizophrenia | Other | Unknown | Controls | Total |
|---|---|---|---|---|---|---|---|
| Aberdeen, UK | 0 | 0 | 564 | 0 | 1 | 331 | 896 |
| Amsterdam, NED | 1,212 | 21 | 1 | 58 | 17 | 1,611 | 2,920 |
| Baltimore, USA | 380 | 0 | 0 | 8 | 0 | 126 | 514 |
| Boston, USA | 3,449 | 52 | 0 | 0 | 0 | 3,498 | 6,999 |
| Cambridge, UK | 0 | 0 | 0 | 0 | 0 | 2,851 | 2,851 |
| Cardiff, UK | 2,442 | 68 | 2,990 | 18 | 0 | 1,106 | 6,624 |
| Dublin, IRE | 180 | 11 | 29 | 3 | 0 | 9 | 232 |
| Edinburgh, UK | 885 | 6 | 304 | 0 | 0 | 64 | 1,259 |
| London, UK | 1,909 | 157 | 1,595 | 0 | 0 | 1,203 | 4,864 |
| Stockholm, SWE | 5,160 | 1 | 0 | 0 | 0 | 5,541 | 10,702 |
| Umea, SWE | 472 | 0 | 0 | 0 | 0 | 459 | 931 |
| Wurzburg, GER | 397 | 0 | 0 | 0 | 14 | 414 | 825 |
| Total | 16,486 | 316 | 5,483 | 87 | 32 | 17,213 | 39,617 |
Within the collection of Bipolar cases, we have subtype information: Bipolar 1, and Bipolar 2. Further splitting the cases and labelling Bipolar cases for whom we do not have subtype information available, we obtain the following numbers of samples in each subcategory:
| Location | Bipolar Disorder 1 | Bipolar Disorder 2 | Bipolar Disorder NOS | Schizoaffective | Bipolar Total (including schizoaffective) | Controls | Total |
|---|---|---|---|---|---|---|---|
| Aberdeen, UK | 0 | 0 | 0 | 0 | 0 | 331 | 331 |
| Amsterdam, NED | 1,032 | 169 | 10 | 21 | 1,233 | 1,611 | 2,844 |
| Baltimore, USA | 358 | 9 | 5 | 0 | 380 | 126 | 506 |
| Boston, USA | 2,122 | 390 | 576 | 52 | 3,501 | 3,498 | 6,999 |
| Cambridge, UK | 0 | 0 | 0 | 0 | 0 | 2,851 | 2,851 |
| Cardiff, UK | 1,518 | 772 | 67 | 68 | 2,510 | 1,106 | 3,616 |
| Dublin, IRE | 180 | 0 | 0 | 11 | 191 | 9 | 200 |
| Edinburgh, UK | 368 | 114 | 2 | 6 | 891 | 64 | 955 |
| London, UK | 1,309 | 372 | 0 | 157 | 2,066 | 1,203 | 3,269 |
| Stockholm, SWE | 2,364 | 1,753 | 905 | 1 | 5,161 | 5,541 | 10,702 |
| Umea, SWE | 320 | 149 | 3 | 0 | 472 | 459 | 931 |
| Wurzburg, GER | 216 | 159 | 15 | 0 | 397 | 414 | 811 |
| Total | 9,787 | 3,887 | 1,583 | 316 | 16,802 | 17,213 | 34,015 |
Additionally, for a subset of the available phenotype data, we also have information regarding psychosis diagnosis and age of onset according to three definitions and two age groupings. Restricting to the subset of cohorts for which we have psychosis information, the breakdown is as follows:
| Location | Bipolar Disorder with Psychosis | Bipolar Disorder without Psychosis | Total |
|---|---|---|---|
| Boston, USA | 667 | 172 | 839 |
| Cardiff, UK | 1,168 | 777 | 1,945 |
| London, UK | 1,095 | 584 | 1,679 |
| Stockholm, SWE | 2,161 | 2,394 | 4,555 |
| Wurzburg, GER | 59 | 338 | 397 |
| Total | 5,150 | 4,265 | 9,415 |
The age of onset categories we have data for are: age at first impairment, age at first symptoms, and age at first diagnosis. Each of these are then binned into two different partitions ‘24’ and ‘40’, according to the following rules:
‘24’ partition
Age of onset < 12 \(\rightarrow\) 0
Age of onset < 12-24 \(\rightarrow\) 1
Age of onset > 24 \(\rightarrow\) 2
‘40’ partition
Age of onset < 18 \(\rightarrow\) 0
Age of onset < 18-40 \(\rightarrow\) 1
Age of onset > 40 \(\rightarrow\) 2
The breakdown of the age of onset categories is as follows:
| Location | Age First Impairment ‘24’ | Age First Impairment ‘40’ | Age First Symptoms ‘24’ | Age First Symptoms ‘40’ | Age at Diagnosis ‘24’ | Age at Diagnosis ‘40’ |
|---|---|---|---|---|---|---|
| Boston, USA | 0 | 0 | 0 | 0 | 0 | 514 |
| Cardiff, UK | 1,308 | 1,308 | 1,199 | 1,199 | 0 | 0 |
| London, UK | 1,808 | 1,808 | 0 | 0 | 0 | 0 |
| Stockholm, SWE | 561 | 561 | 2,114 | 0 | 1,927 | 1,927 |
| Total | 3,677 | 3,677 | 3,313 | 1,199 | 1,927 | 2,441 |
Within each of these age of onset category splits, the age breakdown is then:
Age at first impairment
| Location | Age First Impairment <12 | Age First Impairment 12-24 | Age First Impairment >24 | Total ‘24’ | Age First Impairment <18 | Age First Impairment 18-40 | Age First Impairment >40 | Total ‘40’ |
|---|---|---|---|---|---|---|---|---|
| Cardiff, UK | 80 | 824 | 404 | 1,308 | 469 | 782 | 57 | 1,308 |
| London, UK | 78 | 978 | 752 | 1,808 | 446 | 1,188 | 174 | 1,808 |
| Stockholm, SWE | 26 | 256 | 279 | 561 | 135 | 355 | 71 | 561 |
| Total | 184 | 2,058 | 1,435 | 3,677 | 1,050 | 2,325 | 302 | 3,677 |
Age at first symptoms
| Location | Age First Symptoms <12 | Age First Symptoms 12-24 | Age First Symptoms >24 | Total ‘24’ | Age First Symptoms <18 | Age First Symptoms 18-40 | Age First Symptoms >40 | Total ‘40’ |
|---|---|---|---|---|---|---|---|---|
| Cardiff, UK | 215 | 757 | 227 | 1,199 | 684 | 481 | 34 | 1,199 |
| Stockholm, SWE | 253 | 1,148 | 713 | 2,114 | 0 | 0 | 0 | 0 |
| Total | 468 | 1,905 | 940 | 3,313 | 684 | 481 | 34 | 1,199 |
Age at first diagnosis
| Location | Age First Diagnosis <12 | Age First Diagnosis 12-24 | Age First Diagnosis >24 | Total ‘24’ | Age First Diagnosis <18 | Age First Diagnosis 18-40 | Age First Diagnosis >40 | Total ‘40’ |
|---|---|---|---|---|---|---|---|---|
| Boston, USA | 0 | 0 | 0 | 0 | 224 | 214 | 76 | 514 |
| Stockholm, SWE | 60 | 891 | 976 | 1,927 | 408 | 1,247 | 272 | 1,927 |
| Total | 60 | 891 | 976 | 1,927 | 632 | 1,461 | 348 | 2,441 |
Finally, the split by PI was as follows:
| PI | Bipolar Disorder 1 | Bipolar Disorder 2 | Bipolar Disorder NOS | Schizoaffective | Bipolar Total (including schizoaffective) | Schizophrenia | Other | Unknown | Controls | Total |
|---|---|---|---|---|---|---|---|---|---|---|
| Andreas Reif | 216 | 159 | 15 | 0 | 397 | 0 | 0 | 14 | 414 | 825 |
| Andrew McQuillin | 1,309 | 372 | 0 | 157 | 2,066 | 1,595 | 0 | 0 | 1,203 | 4,864 |
| Bob Yolken | 117 | 9 | 5 | 0 | 139 | 0 | 8 | 0 | 126 | 273 |
| Danielle Posthuma | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 948 | 949 |
| David St Clair | 0 | 0 | 0 | 0 | 0 | 564 | 0 | 1 | 331 | 896 |
| Derek Morris | 180 | 0 | 0 | 11 | 191 | 29 | 3 | 0 | 9 | 232 |
| Douglas Blackwood | 368 | 114 | 2 | 6 | 891 | 304 | 0 | 0 | 64 | 1,259 |
| Fernando Goes | 241 | 0 | 0 | 0 | 241 | 0 | 0 | 0 | 0 | 241 |
| Jordan Smoller | 2,122 | 390 | 576 | 52 | 3,501 | 0 | 0 | 0 | 3,498 | 6,999 |
| Michael ODonovan | 0 | 0 | 0 | 11 | 11 | 2,986 | 1 | 0 | 0 | 2,998 |
| Michael Owen | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,106 | 1,106 |
| Mikael Landen | 2,364 | 1,753 | 905 | 1 | 5,161 | 0 | 0 | 0 | 761 | 5,922 |
| Nancy Pedersen | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4,780 | 4,780 |
| Nick Craddock | 1,518 | 772 | 67 | 57 | 2,499 | 4 | 17 | 0 | 0 | 2,520 |
| Roel Ophoff | 1,032 | 169 | 10 | 21 | 1,233 | 1 | 58 | 16 | 663 | 1,971 |
| Rolf Adolfsson | 320 | 149 | 3 | 0 | 472 | 0 | 0 | 0 | 459 | 931 |
| Willem Ouwehand | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2,851 | 2,851 |
| Total | 9,787 | 3,887 | 1,583 | 316 | 16,802 | 5,483 | 87 | 32 | 17,213 | 39,617 |
For our QC pipeline, we first read in the .vcf file, split multiallelics, and remove sites with more than 6 alleles. After splitting muliallelics in the .vcf file containing 29,911,479 variants and restricting to these sites, we have 37,344,246 variants.
Initial genotype filtering
Our first step (after conversion of the joint called .vcf file to a hail matrix table) is to remove genotypes based on the following collection of criteria:
- If homozygous reference, remove if at least one of the following is true:
- Genotype quality \(<\) 20
- Depth \(<\) 10
- If heterozygous, at least one of the following is true:
- (Reference allele depth + alternative allele depth) divided by total depth \(<\) 0.8
- Alternative allele depth divided by total depth \(<\) 0.2
- Reference phred-scaled genotype posterior \(<\) 20
- Depth \(<\) 10
- If homozygous variant, at least one of the following is true:
- Alternative allele depth divided by total depth \(<\) 0.8
- Reference phred-scaled genotype posterior \(<\) 20
- Depth \(<\) 10
Initial variant filtering
Remove variants that either:
- Fall in a low complexity region
- Fail variant quality score recalibration (VQSR)
- Fall outside padded target intervals (50bp padding)
- Are invariant after the initial GT filter
| Filter | Variants | % |
|---|---|---|
| Variants with < 7 alleles | 37,344,246 | 100.0 |
| Failing VQSR | 100,742 | 0.3 |
| In LCRs | 1,215,218 | 3.3 |
| Outside padded target interval | 27,119,165 | 72.6 |
| Invariant sites after initial variant and genotype filters | 3,117,961 | 8.3 |
| Variants after initial filtering | 6,829,373 | 18.3 |
Initial sample quality control
| Filter | Samples | Bipolar cases | Controls | % |
|---|---|---|---|---|
| Initial samples in vcf | 39,618 | 16,486 | 17,212 | 100.0 |
| Unable to obtain both phenotype and sequence information | 2 | NA | NA | 0.0 |
| Unknown phenotype | 32 | NA | NA | 0.1 |
| Low coverage or high contamination | 133 | 72 | 54 | 0.3 |
| Samples after initial filter | 39,451 | 16,414 | 17,158 | 99.6 |
We run the sample_qc function in hail and remove samples according to the following:
- Sample call rate \(<\) 0.93
- FREEMIX contamination (%) \(>\) 0.02
- Percentage chimeras (%) \(>\) 0.015
- Mean depth \(<\) 30
- Mean genotype quality \(<\) 55
Thresholds used were based on plotting the distributions of these metrics. A full collection of plots can be found in the repository. Here we show boxplots with overlaid scatterplots of the above metrics, split by sequencing batch, and coloured by location. The threshold for exclusion is shown as a dashed line.
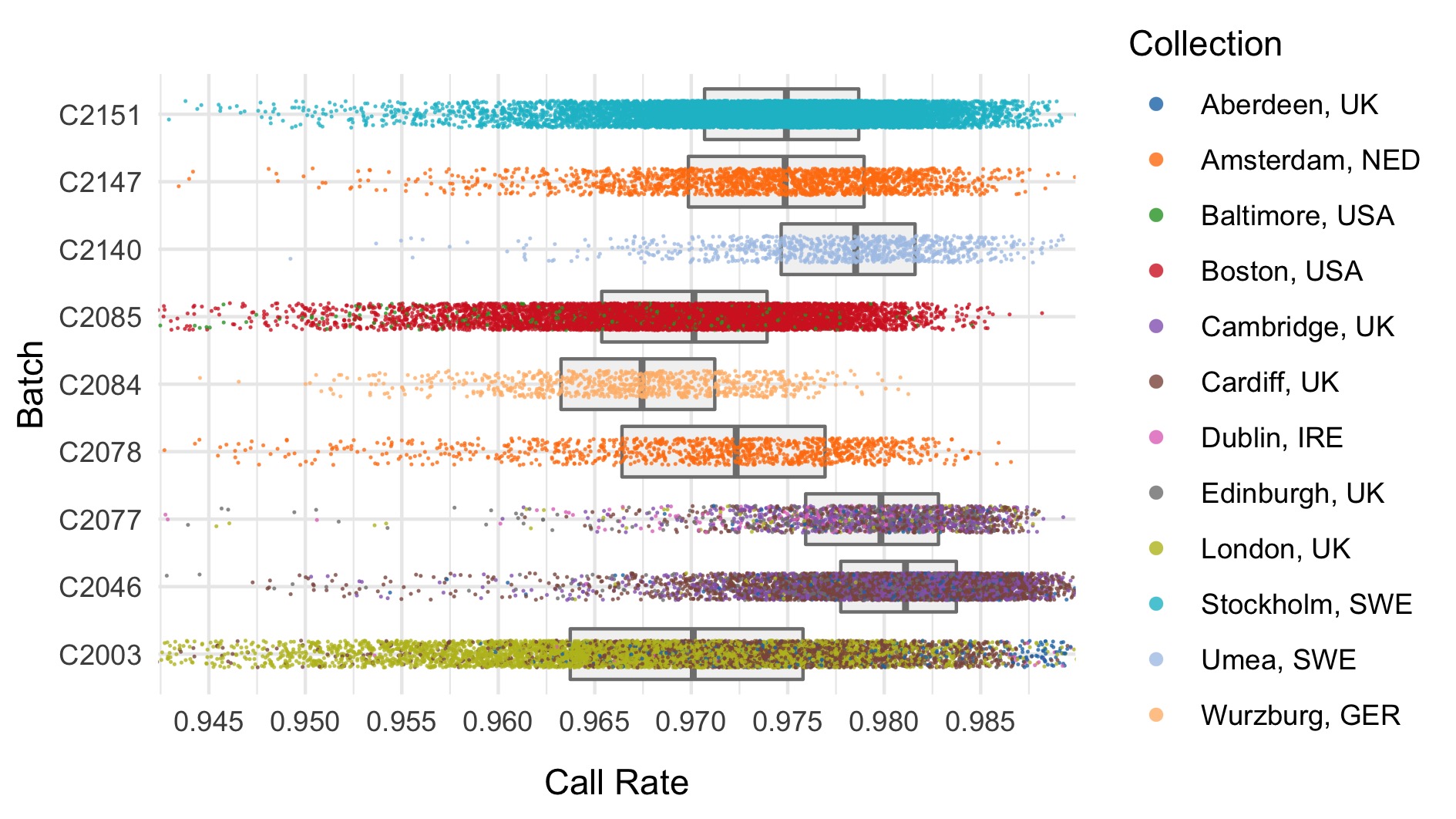
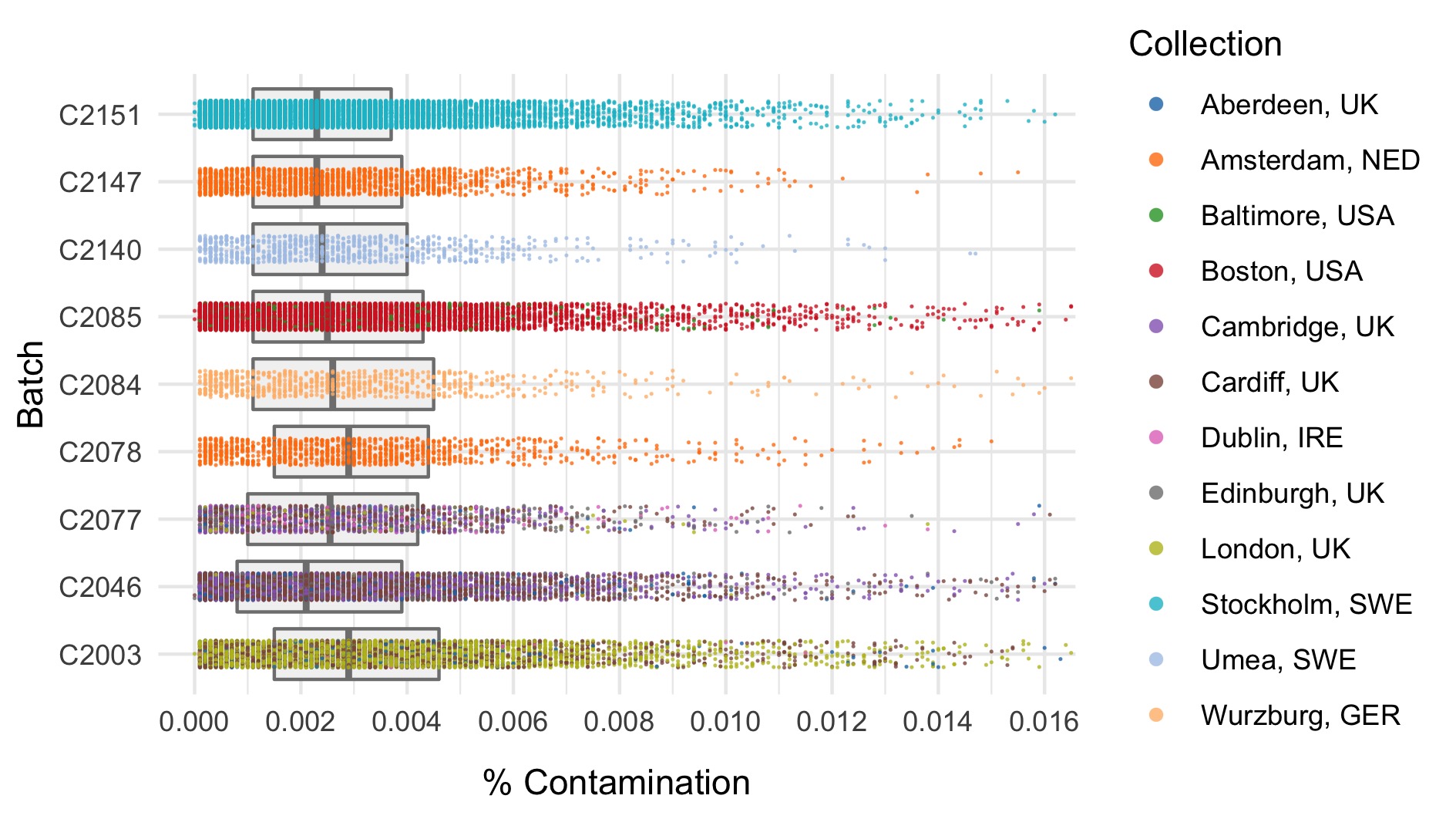
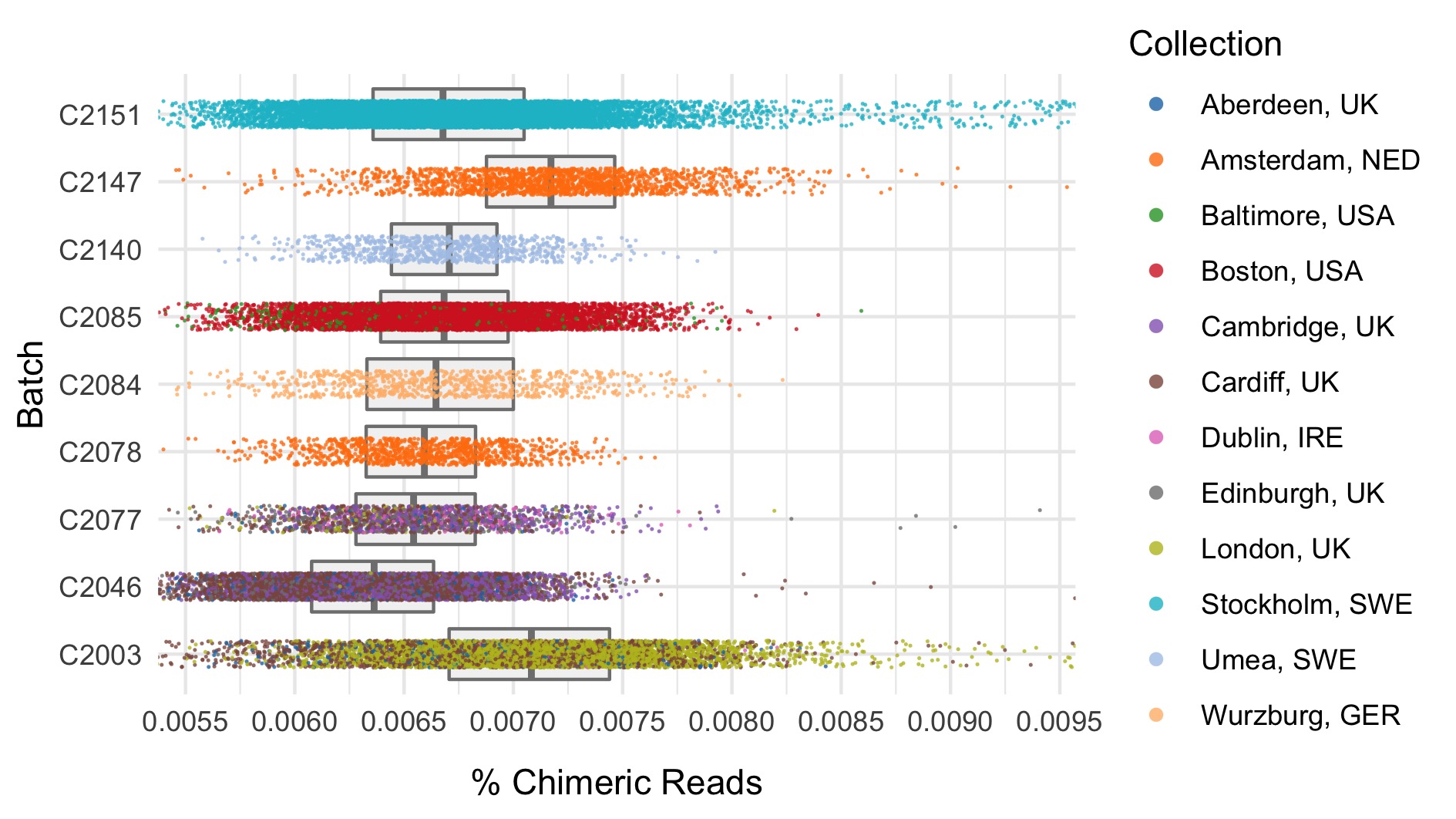
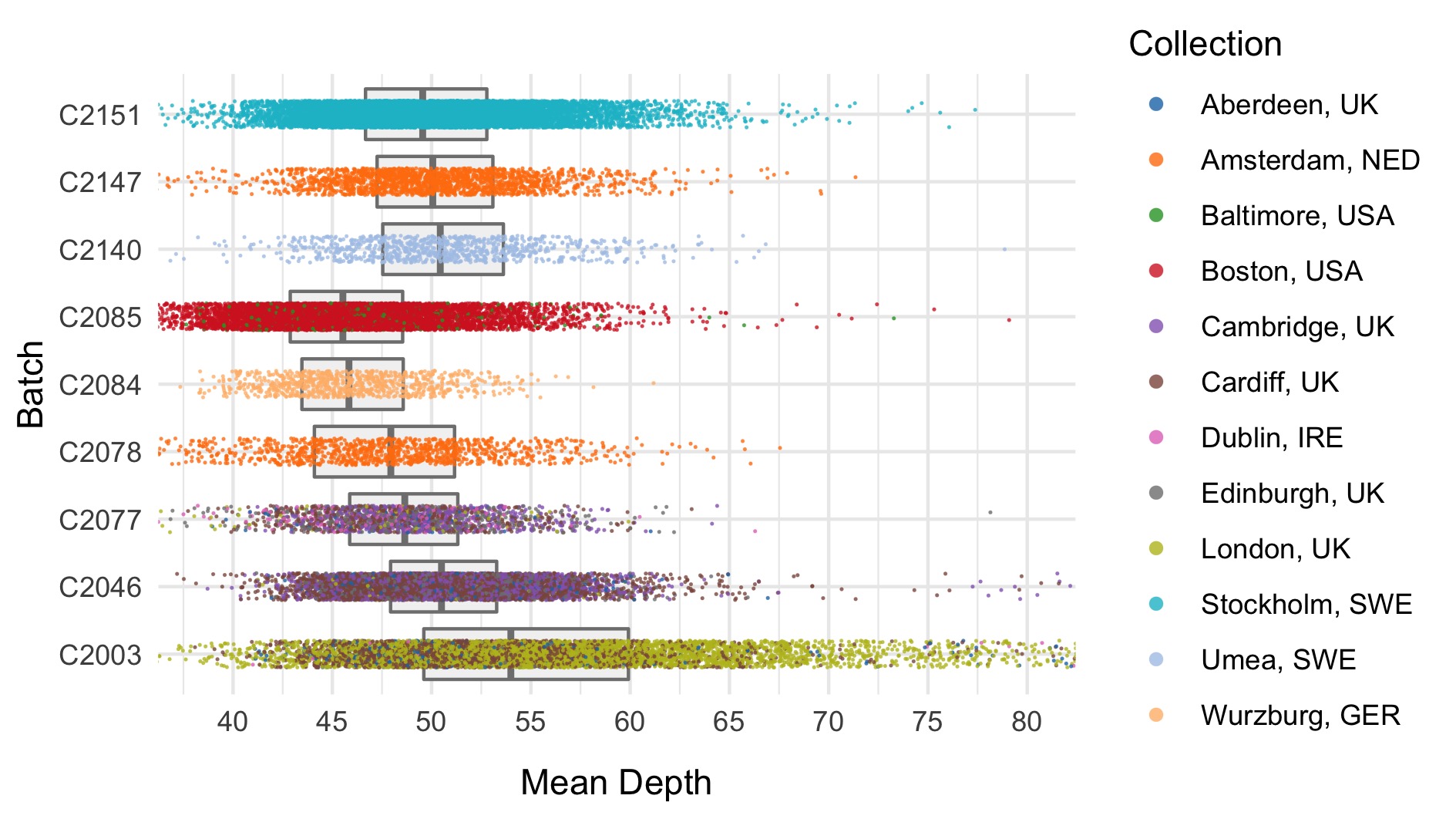
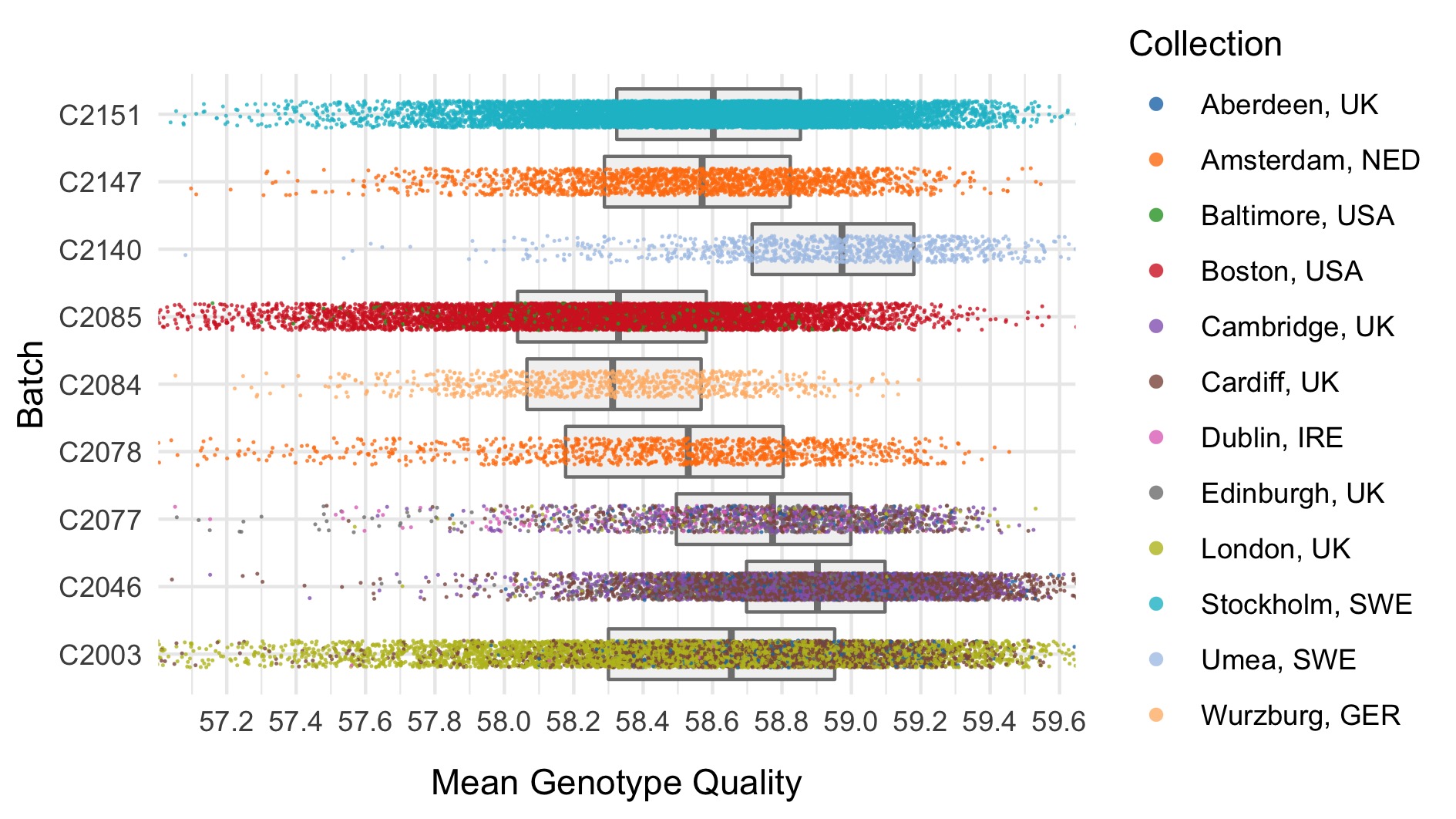
| Filter | Samples | Bipolar cases | Controls | % |
|---|---|---|---|---|
| Samples after initial filter | 39,451 | 16,414 | 17,158 | 100.0 |
| Sample call rate < 0.93 | 185 | 124 | 53 | 0.5 |
| % FREEMIX contamination > 0.02 | 268 | 146 | 104 | 0.7 |
| % chimeric reads > 0.015 | 152 | 49 | 100 | 0.4 |
| Mean DP < 30 | 20 | 5 | 12 | 0.1 |
| Mean GQ < 55 | 56 | 28 | 25 | 0.1 |
| Samples after sample QC filters | 38,894 | 16,138 | 16,906 | 98.6 |
Following this step, we export high quality variants (allele frequency between 0.01 to 0.99 with high call rate (> 0.98)) to plink format and prune to pseudo-independent SNPs using --indep 50 5 2. This pruned set of SNPs feeds into the next few stages of the QC pipeline.
Sex imputation
We impute the sexes of the individuals with this pruned set of variants on the X chromosome, and create list of samples with incorrect or unknown sex as defined by:
- Sex is unknown in the phenotype files
- F-statistic \(>\) 0.6 and the sex is female in the phenotype file
- F-statistic \(<\) 0.6 and the sex is male in the phenotype file
Here we show the distribution of the F-statistic, with the 0.6 threshold defining our sex impututation shown as a dashed line.
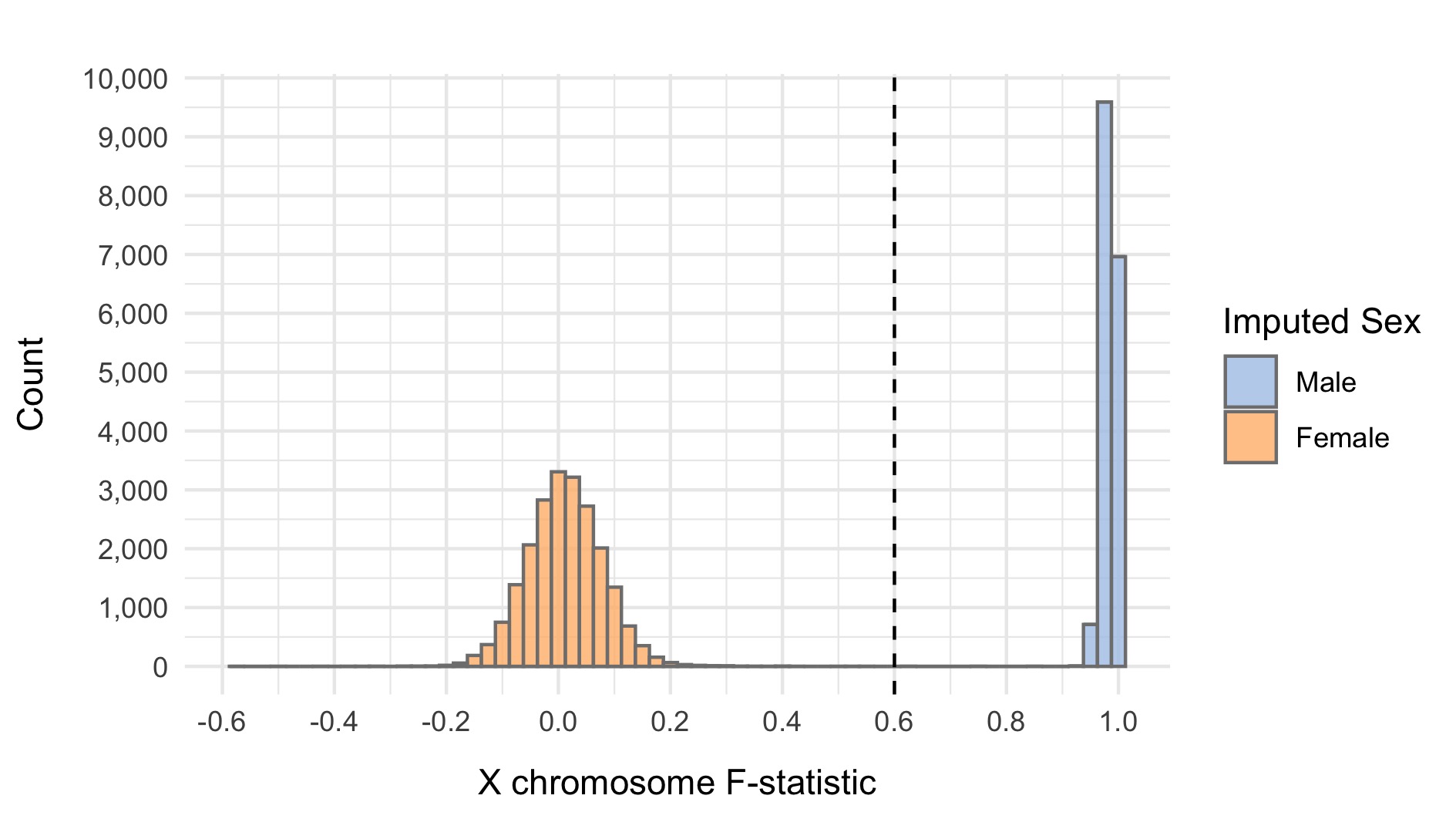
| Filter | Samples | Bipolar cases | Controls | % |
|---|---|---|---|---|
| Samples after sample QC filters | 38,894 | 16,138 | 16,906 | 100.0 |
| Samples with sex swap | 238 | 147 | 52 | 0.6 |
| Samples after sex swap removal | 38,656 | 15,991 | 16,854 | 99.4 |
IBD
Using the identity_by_descent method in hail, we evaluate \(\hat{\pi}\) between pairs of samples, and filter based on a threshold of 0.2 shown as a dashed line on the plot below.
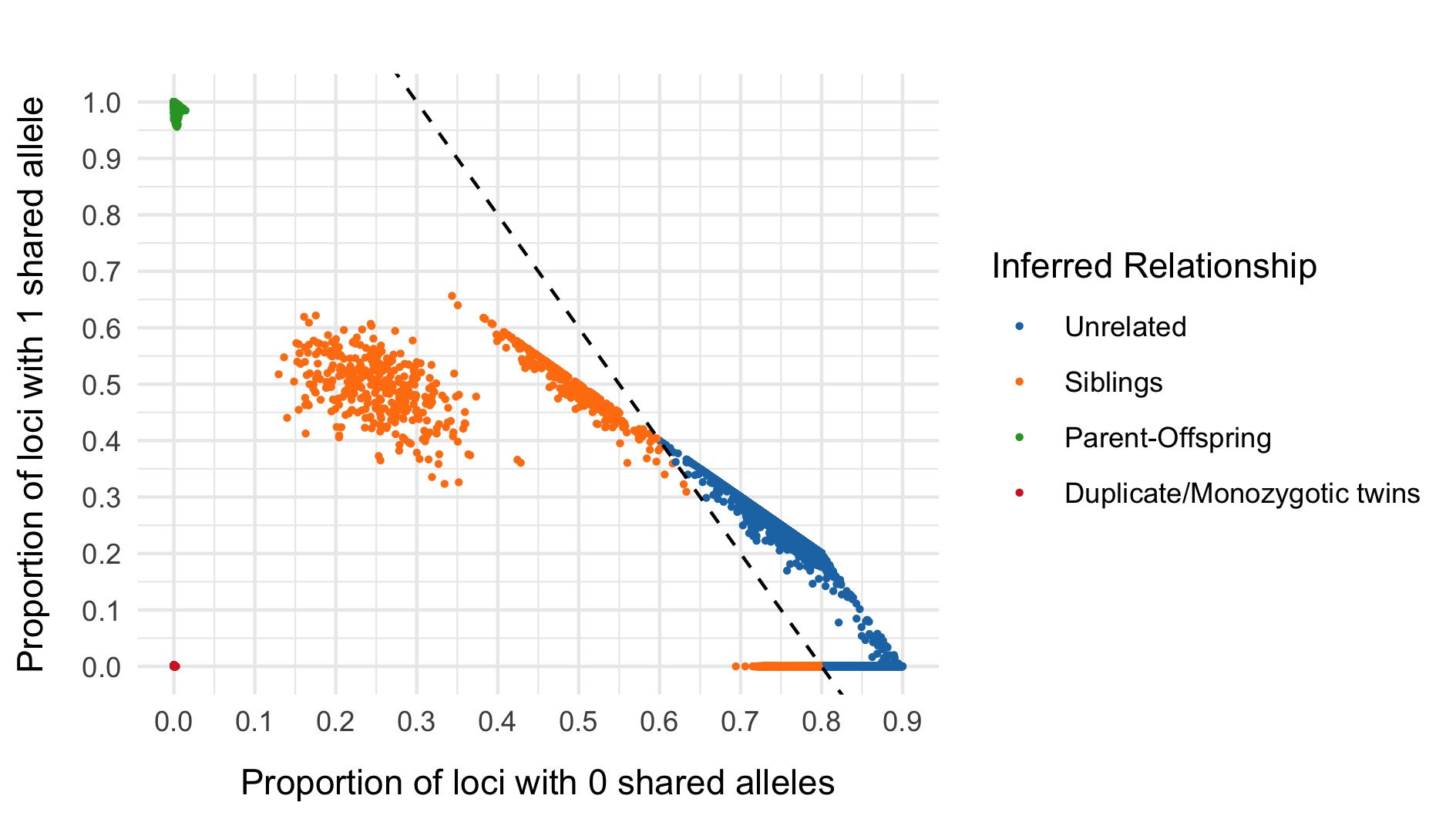
We then create a sample list of patients such that no pair has \(\hat{\pi} >\) 0.2.
| Filter | Samples | Bipolar cases | Controls | % |
|---|---|---|---|---|
| Samples after sample QC filters | 38,894 | 16,138 | 16,906 | 100.0 |
| Related samples for removal | 1,716 | 792 | 688 | 4.4 |
| Samples after IBD removal | 37,178 | 15,346 | 16,218 | 95.6 |
PCA
We next perform a number of principal component analysis (PCA) steps to ensure that we have matched cases and controls in our cleaned dataset.
Initial PCA
We first run PCA on samples after removing relateds and those that passed initial QC, using the pruned set of variants.
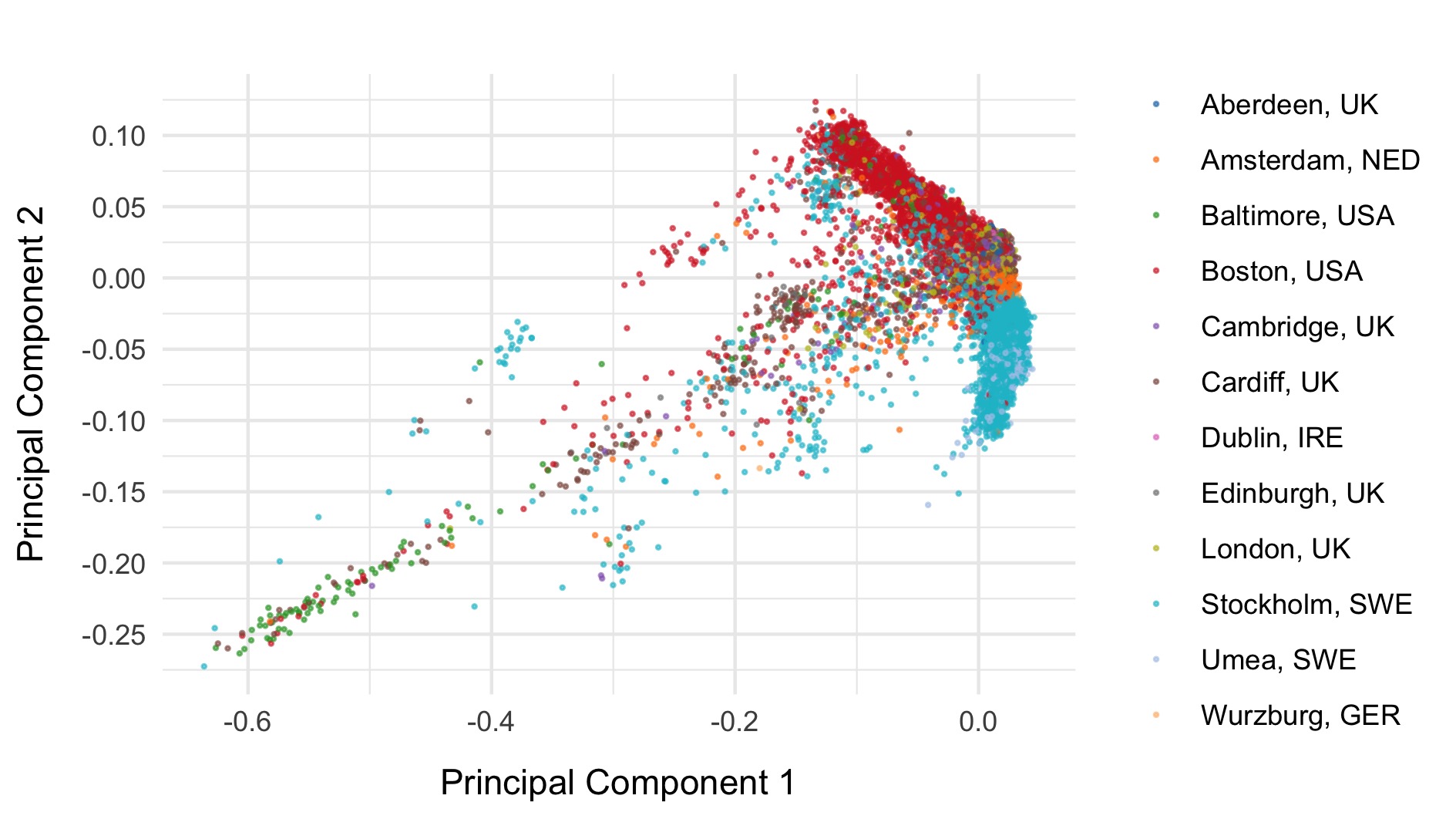
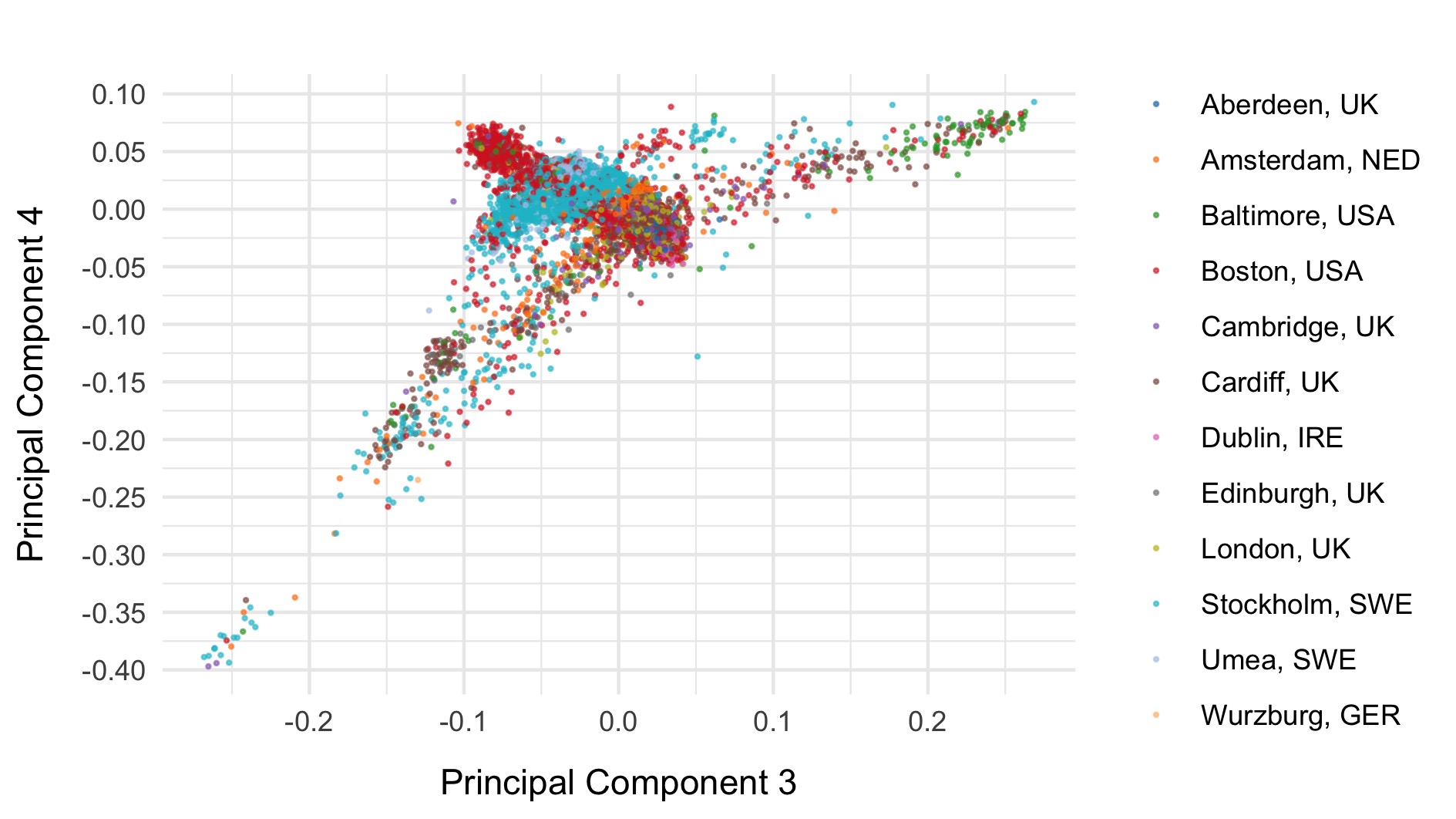
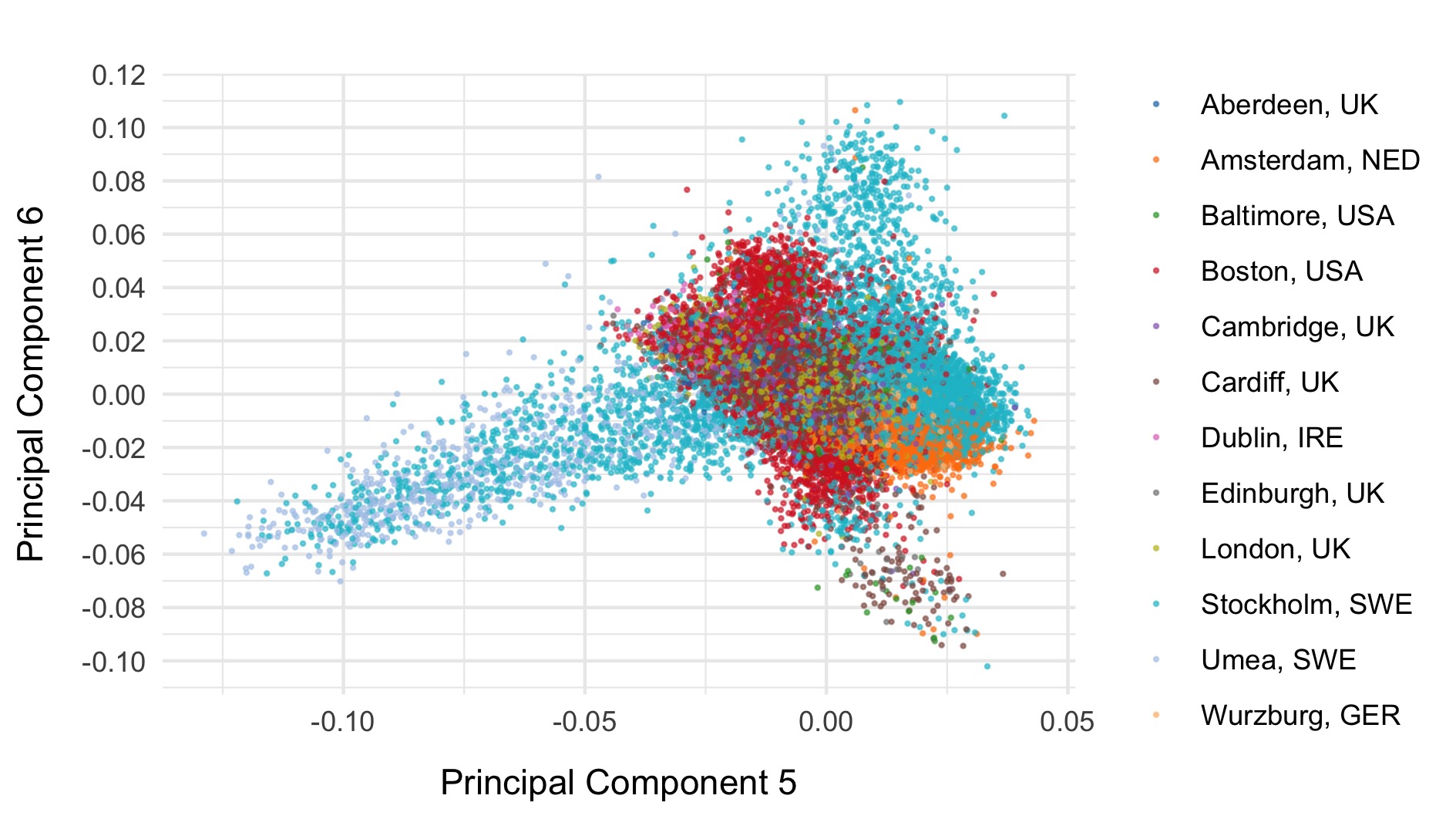
PCA including 1000 genomes
Next, we included the 1000 genomes samples (minus the small subset of related individuals within 1000 geneomes), and rerun PCA after including those individuals. Plots of the first six principal components are shown below. 1000 genomes samples are coloured in dark blue.
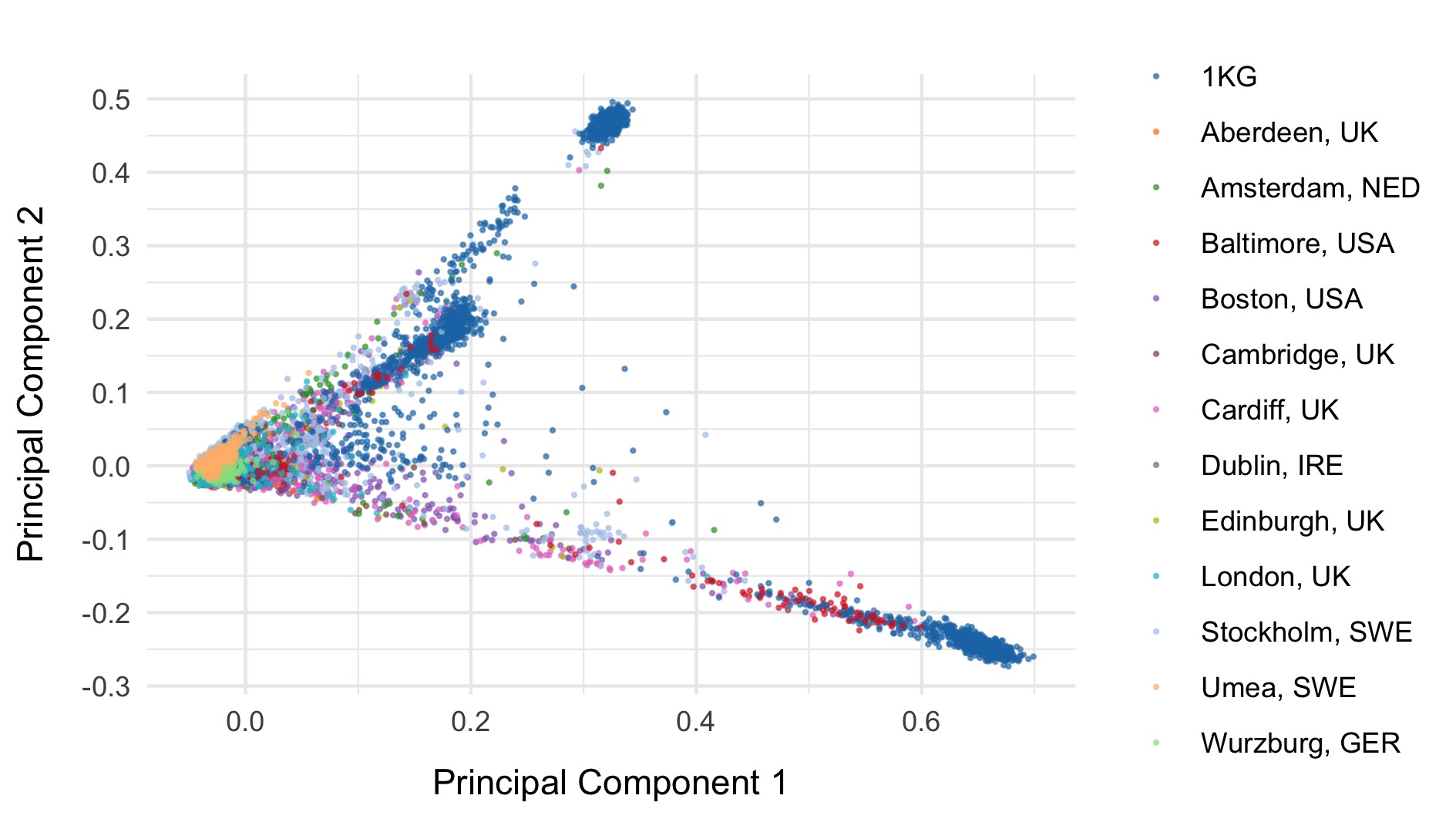
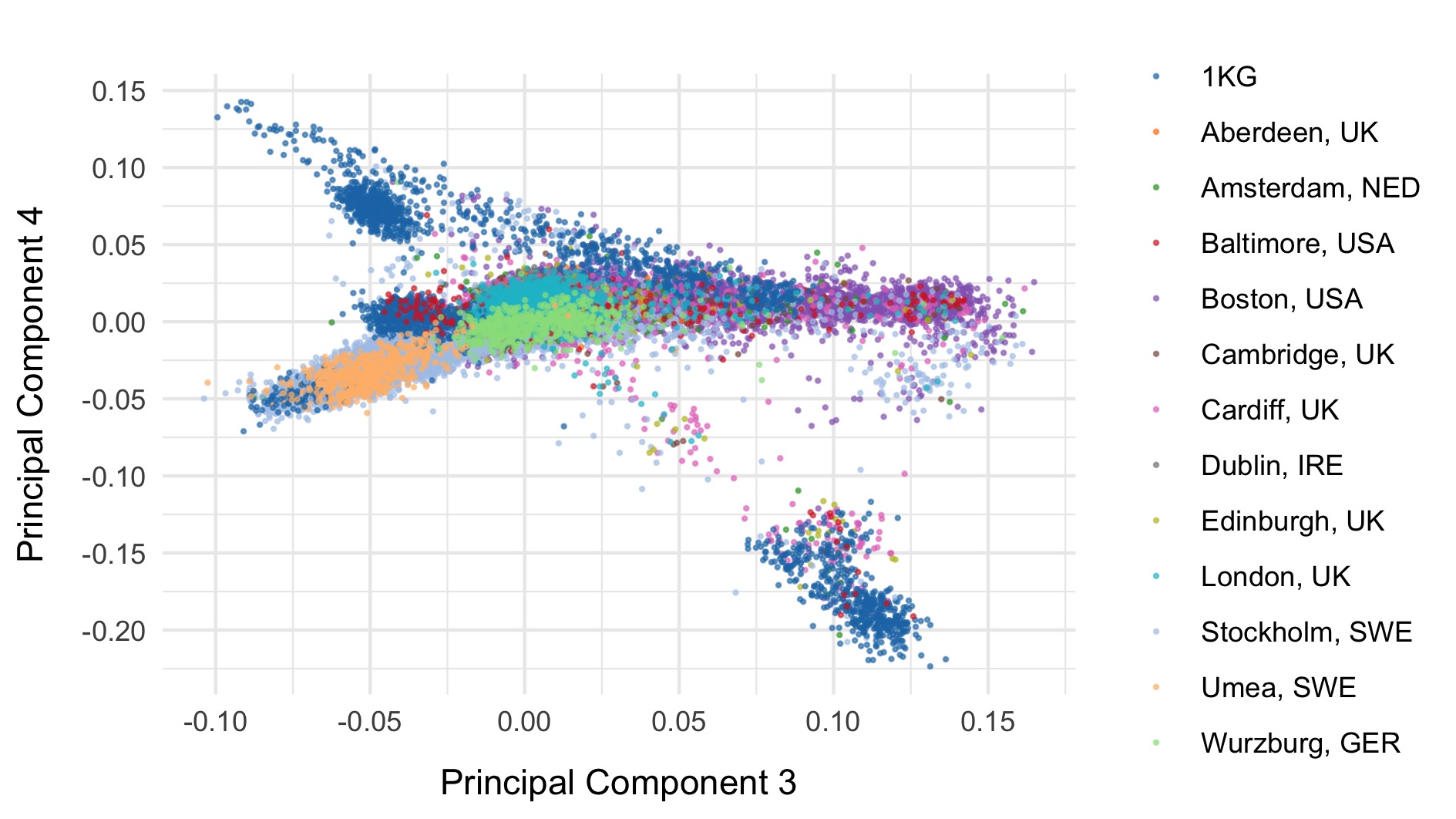
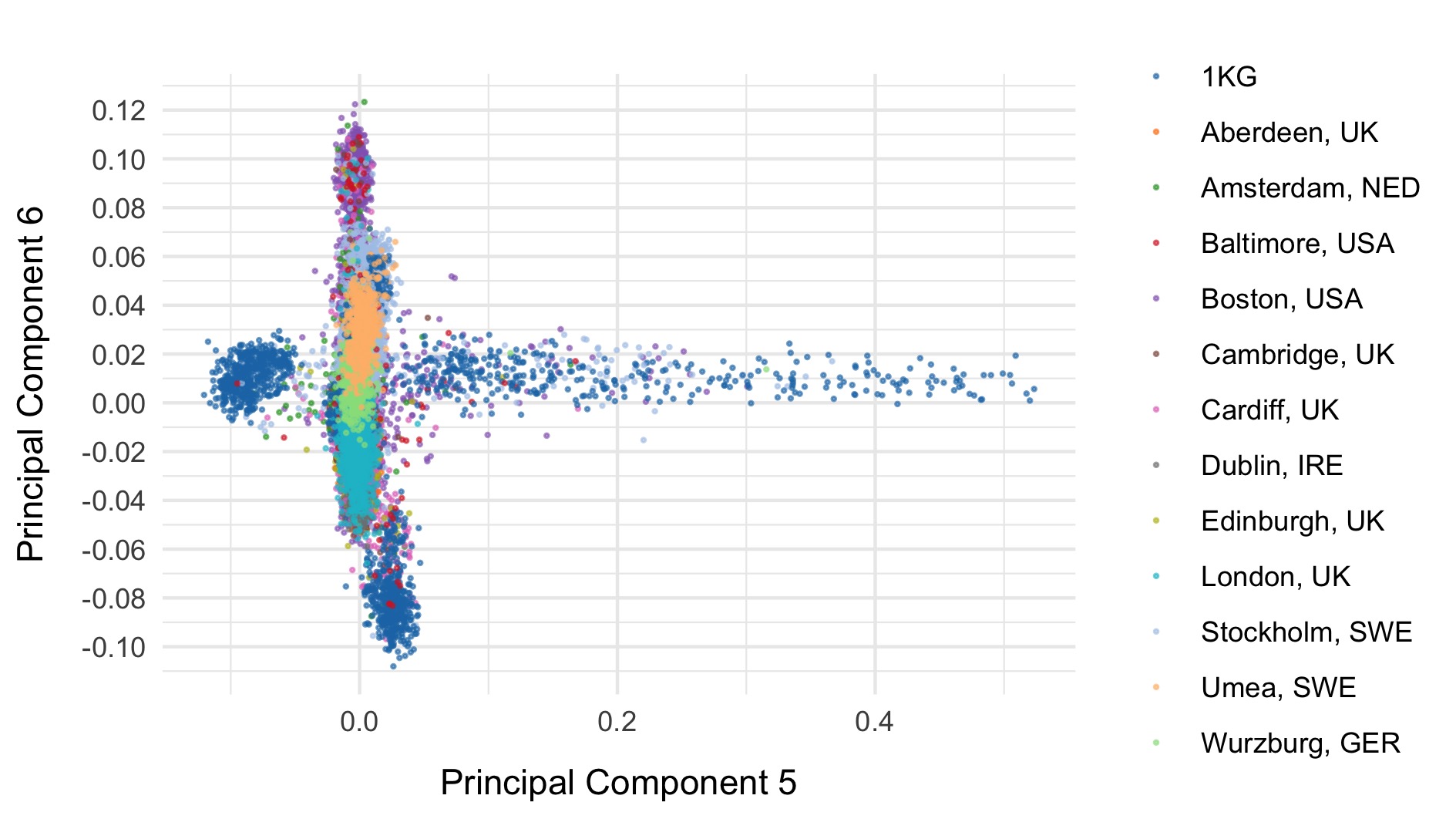
We restrict to the European subset of individuals to perform analysis. To do this, we train a random forest on the super populations labels of 1000 genomes and predict the super population that each of the BipEx samples. We denote strictly defined European subset as those with probability \(>\) 0.95 of being European according to the classifier. BipEx samples are coloured by their assignment or unsure if none of the classifier probabilities exceeded 0.95 in the following plots.
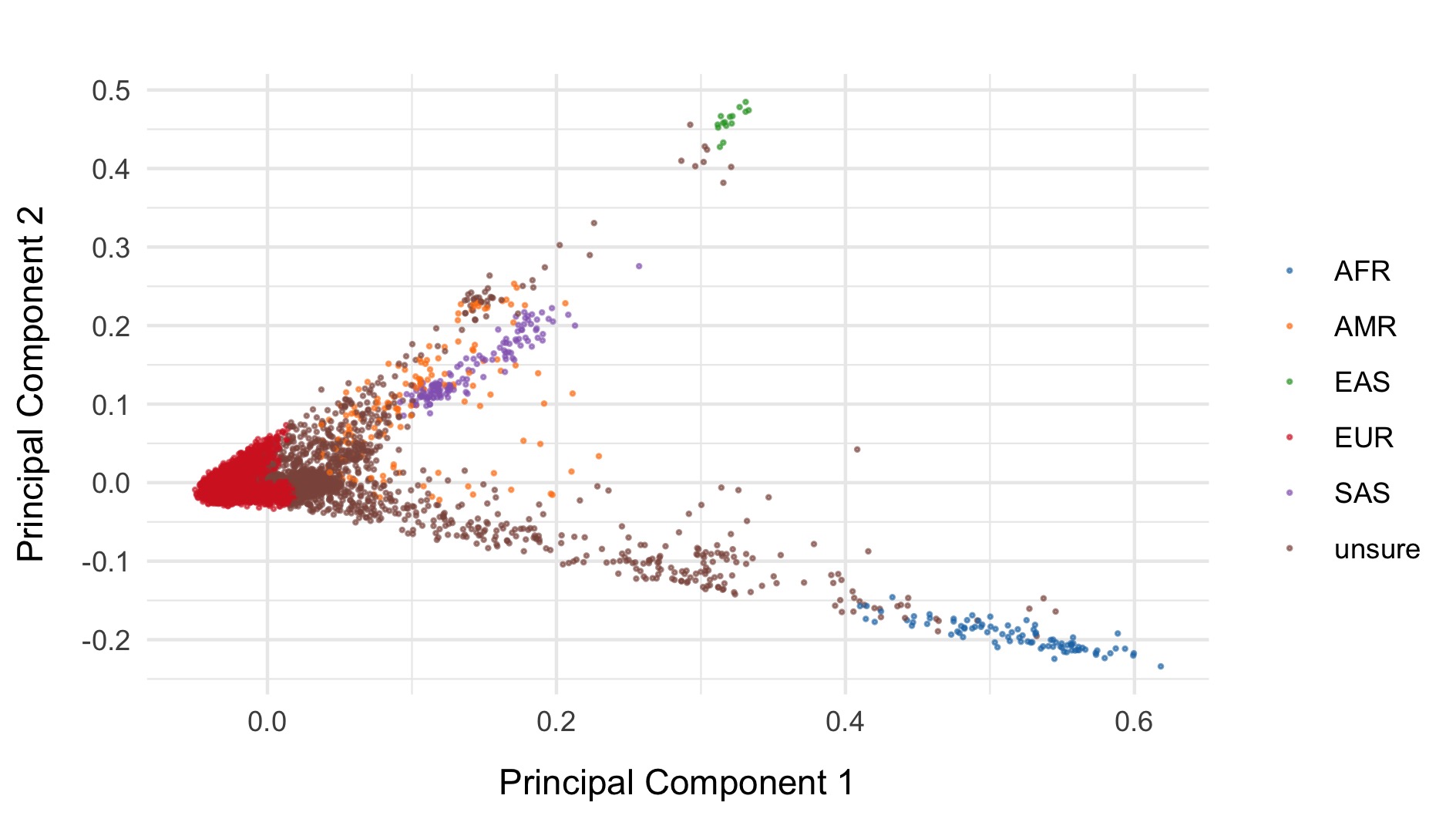
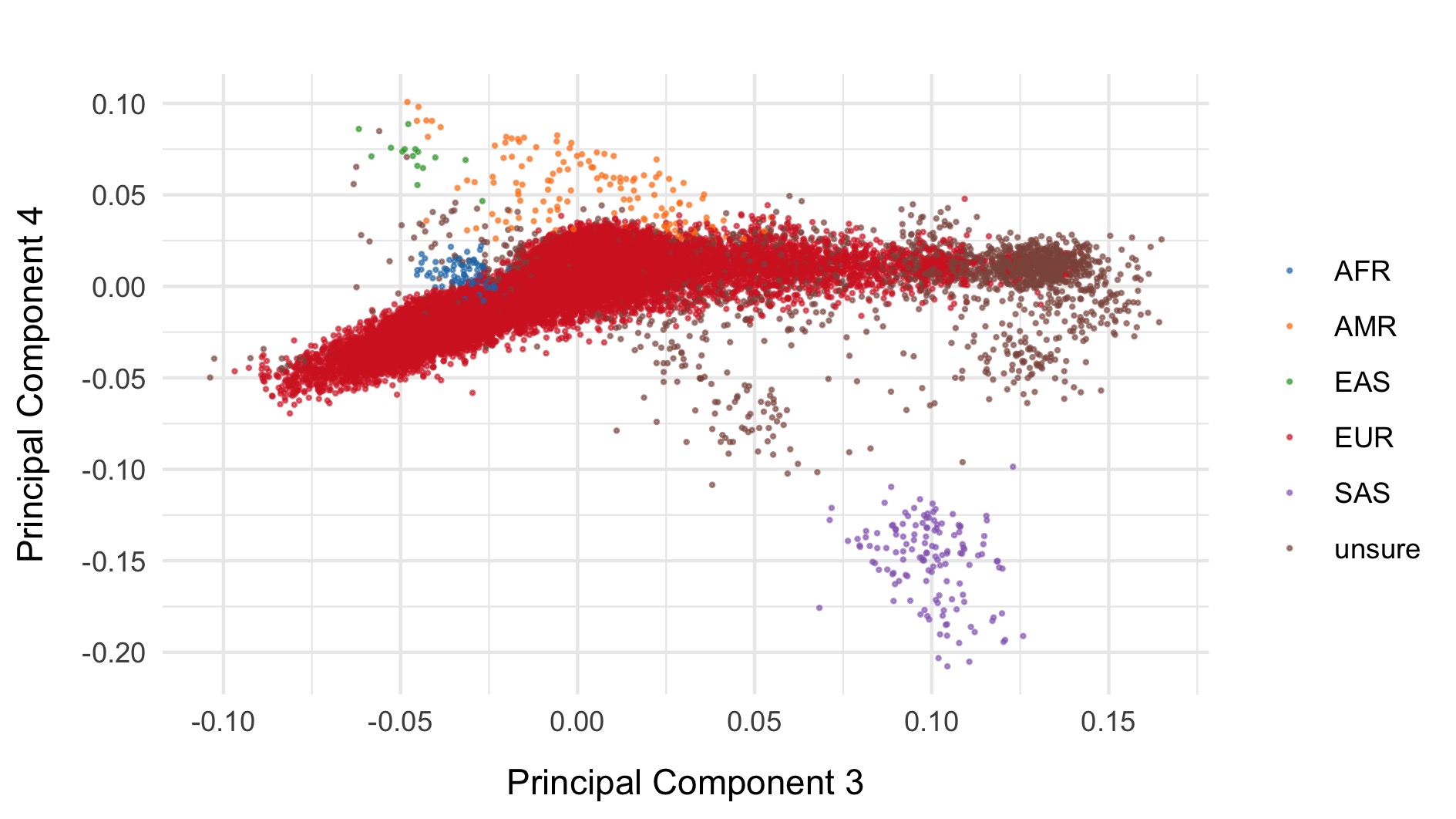
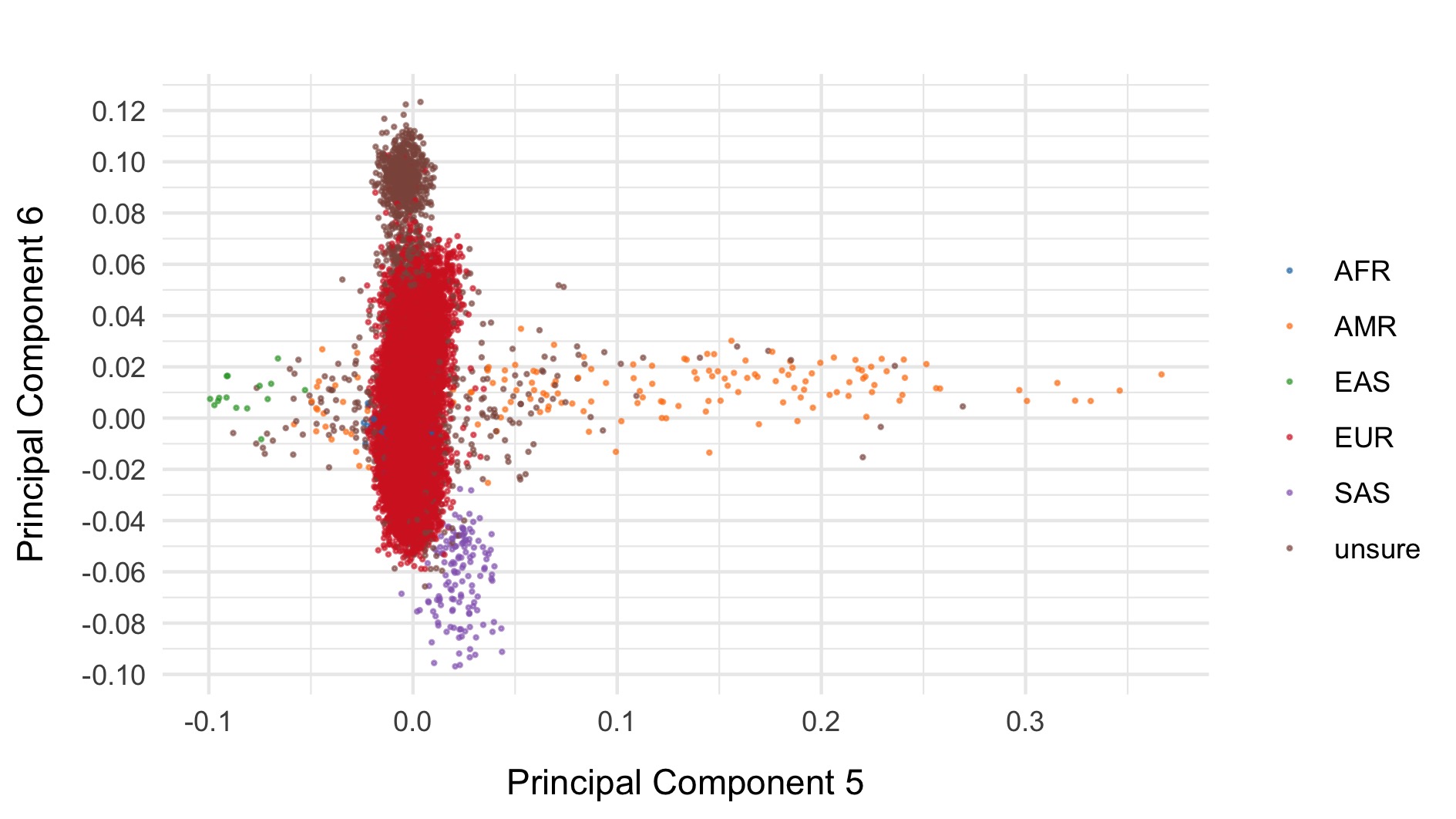
Samples not assigned to the European cluster were removed from downstream analysis.
In addition, using a much looser definition of European, we restrict to US samples from MGH and Johns Hopkins, and run PCA. This enabled us to identify Ashkenazi Jewish clusters, and create a list of outliers (AJ or otherwise) for downstream removal or independent analysis.
Run also ran a further collection of PCAs on:
- Strictly defined Europeans and Ashkenazi Jewish individuals
- Use Ashkenazi Jewish cluster to train a random forest and determine if there are further Ashkenazi Jews in the remainder of the dataset.
- Strictly defined Europeans
| Filter | Samples | Bipolar cases | Controls | % |
|---|---|---|---|---|
| Samples after IBD removal | 37,178 | 15,346 | 16,218 | 100.0 |
| PCA based filters | 2,880 | 1,120 | 1,422 | 7.7 |
| Samples after population filters | 34,298 | 14,226 | 14,796 | 92.3 |
However, upon restriction to the European cluster and after removal of AJs, we find that we have a dense case-control matched collection of samples and so decide not to analyse Swedes, Finns and Europeans (excluding Finns and Swedes) separately.
Final variant filtering
For our final variant filtering step, we first restrict to samples in the strictly defined European subset, filter to the unrelated list, and filter out samples with incorrectly defined sex or unknown sex, and run variant QC. We then evaluate a collection of variant metrics and remove variants that satisfy at least one of:
- Invariant site in cleaned sample subset
- Call rate \(<\) 0.97
- Control call rate \(<\) 0.97
- Case call rate \(<\) 0.97
- \(|\)Case call rate - Control call rate\(| >\) 0.02
- \(p\)-value for Hardy Weinberg Equilibrium \(<\) 10-6
The following plots show the 0.97 threshold for call rate and 0.02 threshold for difference in call rate between cases and controls respectively.
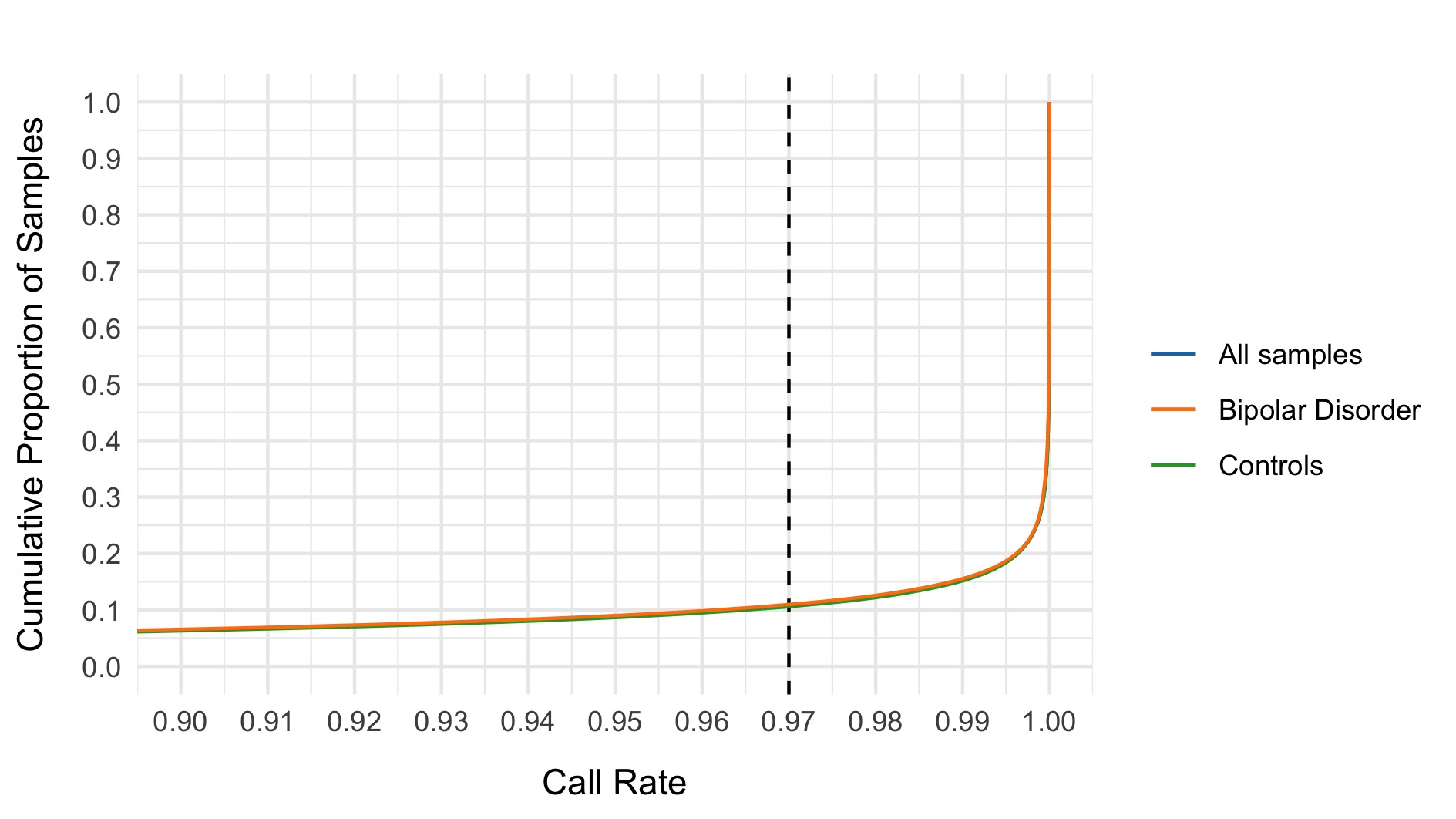
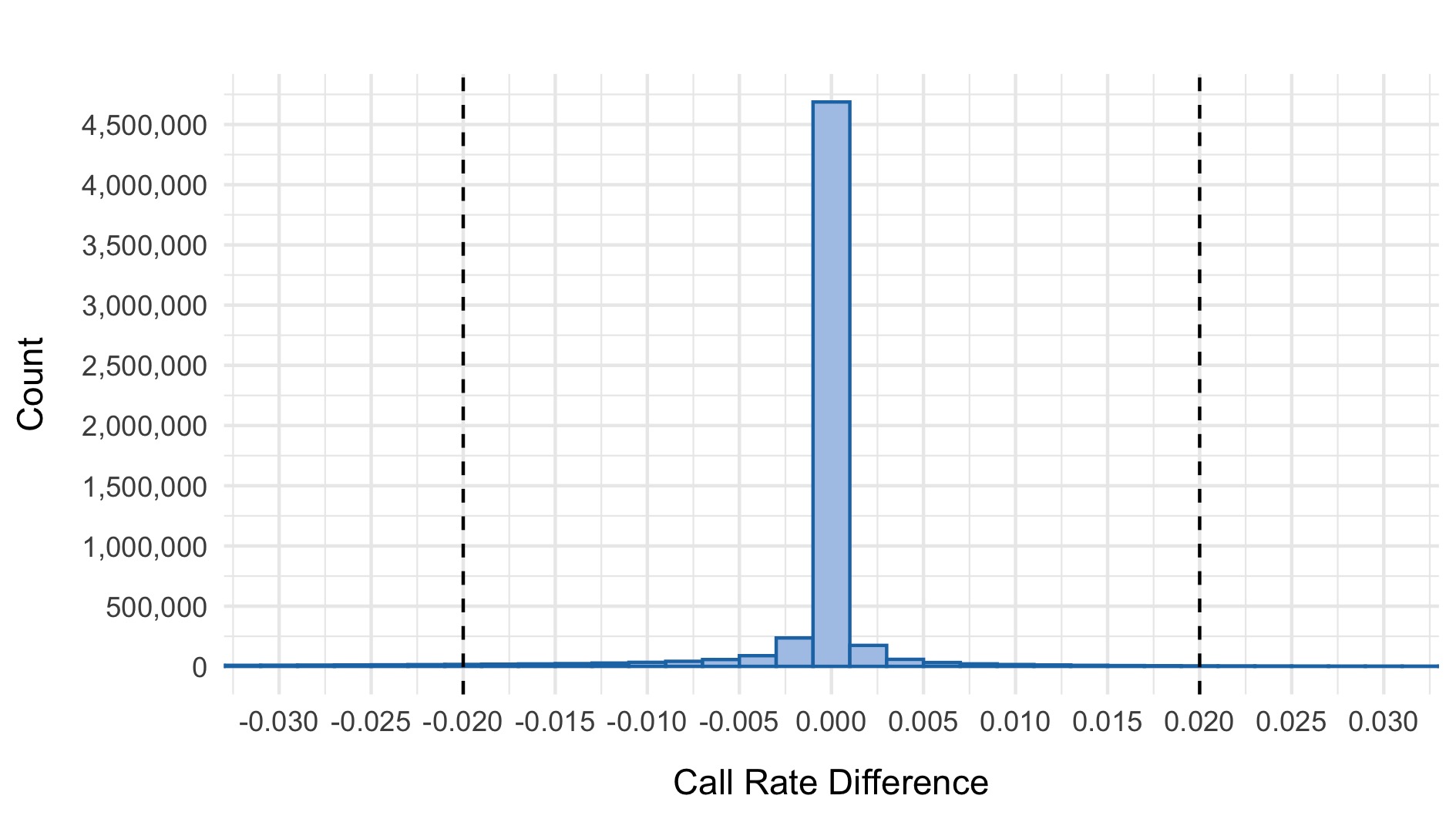
| Filter | Variants | % |
|---|---|---|
| Variants after initial filter | 6,829,373 | 100.0 |
| Invariant sites after sample filters | 1,051,421 | 15.4 |
| Overall variant call rate < 0.97 | 737,072 | 10.8 |
| Overall variant case call rate < 0.97 | 716,709 | 10.5 |
| Overall variant control call rate < 0.97 | 743,659 | 10.9 |
| Difference between case and control variant call rate < 0.02 | 232,341 | 3.4 |
| Variants failing HWE filter | 1,083,479 | 15.9 |
| Variants after filters | 5,104,759 | 74.7 |
After these steps we plot the resulting changes in metrics across the samples in our data set. Each of the following plots splits the data by sequencing data and colours the points based on location. The first collection of subplots in each figure shows the variant metrics before sample removal, with the lower collection of subplots showing the resultant change after our QC steps.
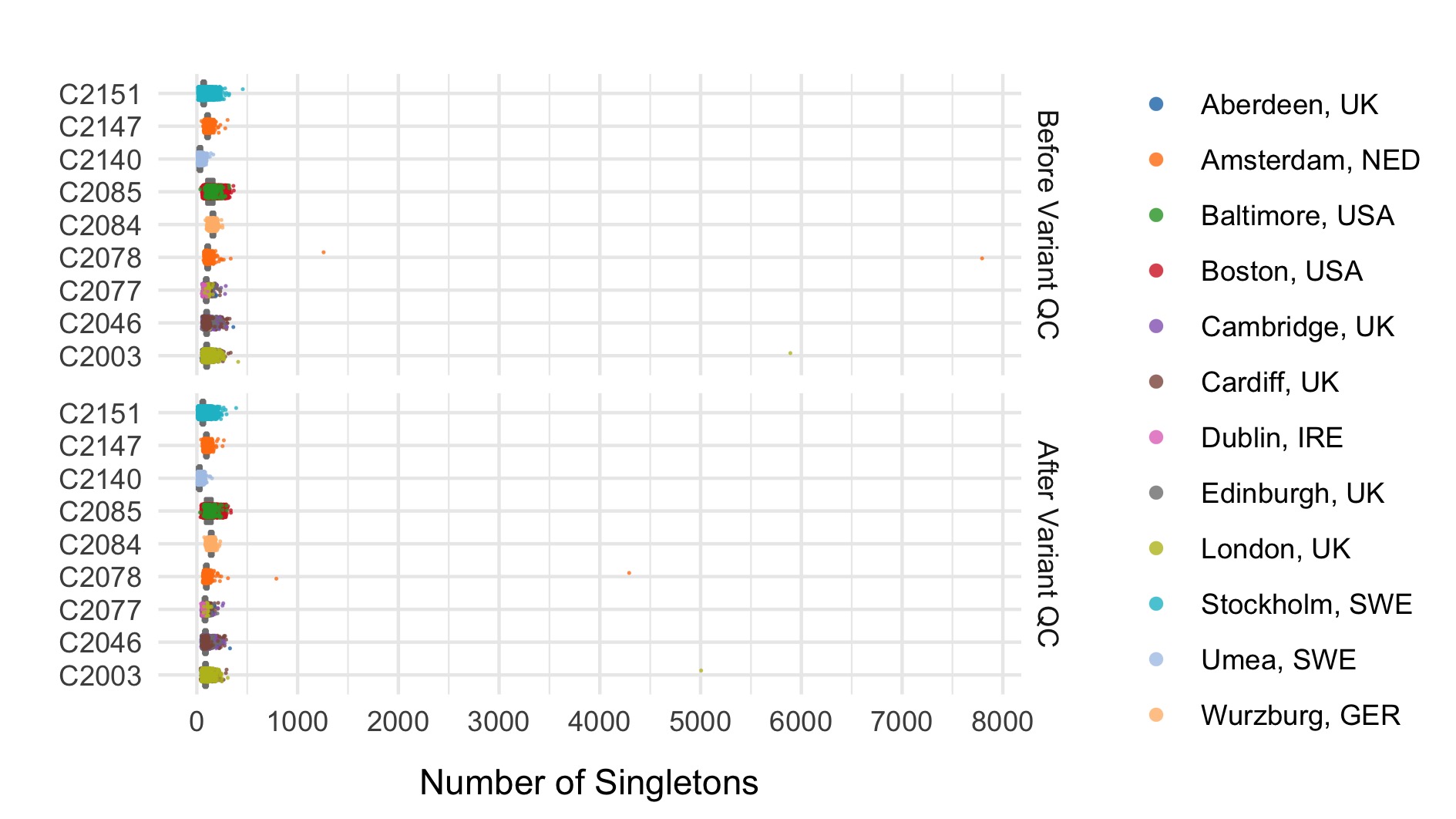
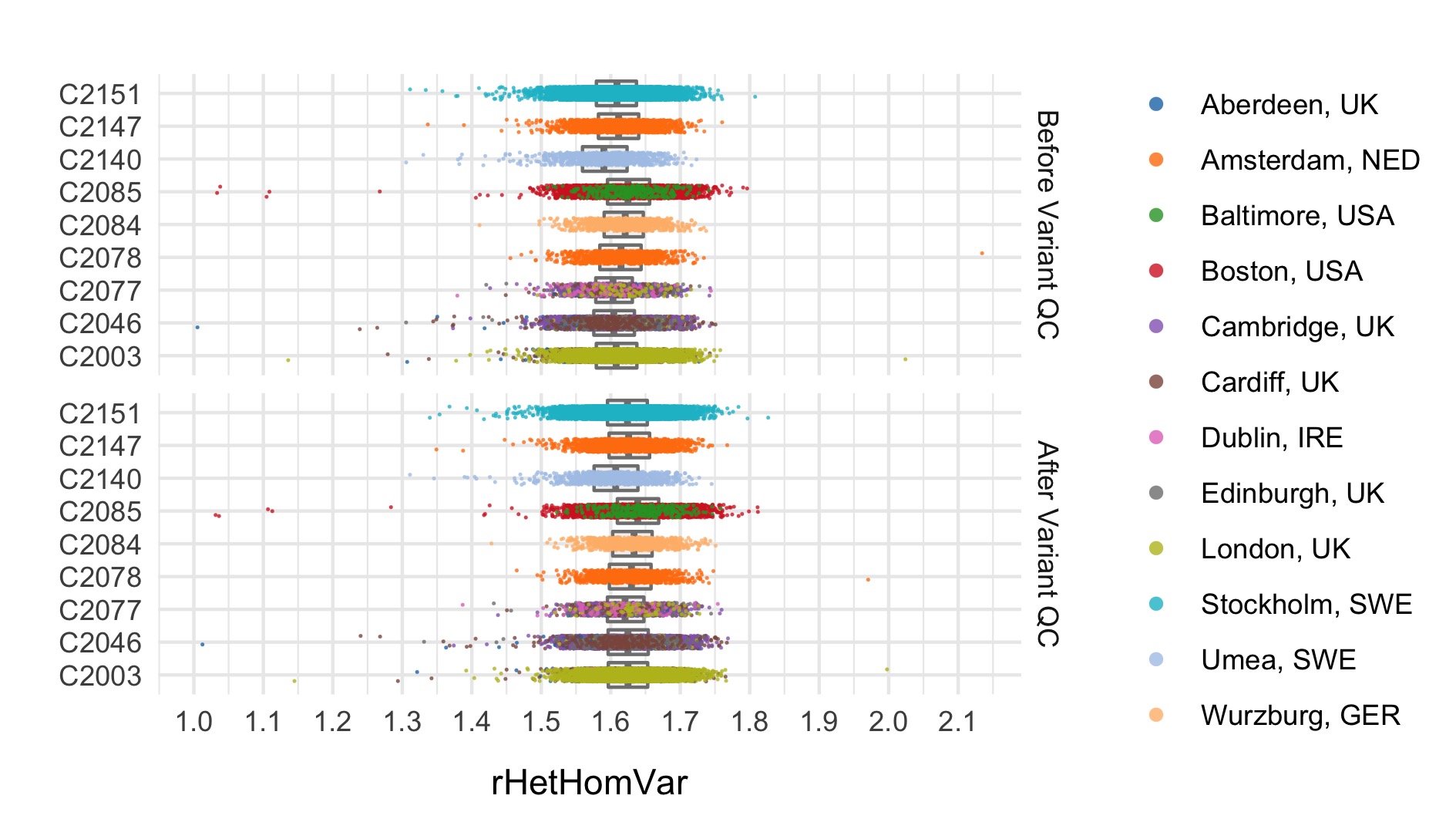
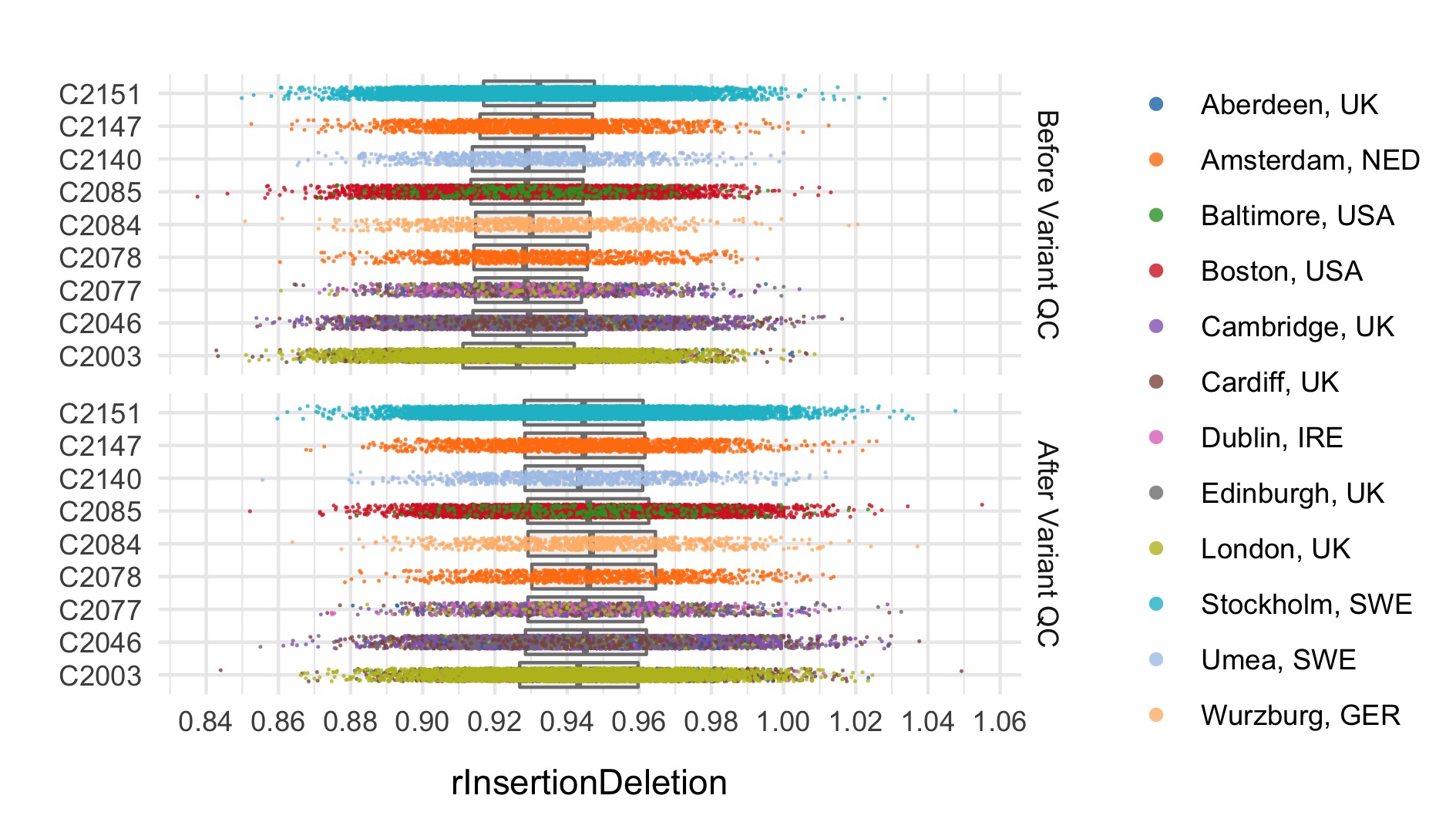
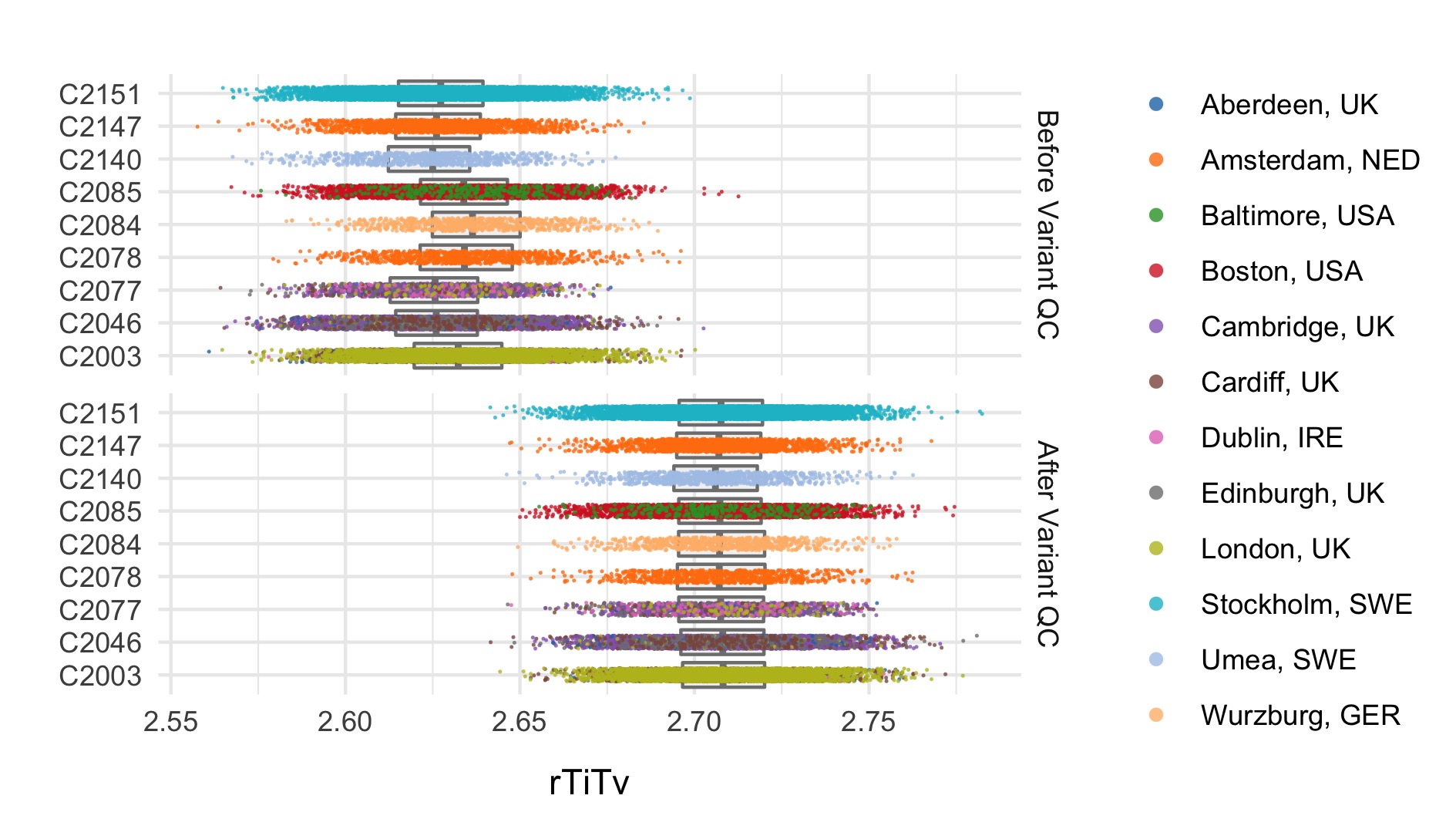
Final sample filtering
In this step we remove sample outliers after the variant cleaning in the previous step. Samples are removed if at least one of the following lies more that three standard deviations away from the mean:
- Ratio of transitions to transversions
- Ratio of heterozygous to homozygous variant
- Ratio of insertions to deletions
- Number of singletons
| Filter | Samples | Bipolar Cases | Controls | % |
|---|---|---|---|---|
| Samples after population filters | 34,298 | 14,226 | 14,796 | 100.0 |
| Within batch Ti/Tv ratio outside 3 standard deviations | 100 | 50 | 42 | 0.3 |
| Within batch Het/HomVar ratio outside 3 standard deviations | 150 | 66 | 58 | 0.4 |
| Within batch Insertion/Deletion ratio outside 3 standard deviations | 93 | 31 | 48 | 0.3 |
| Within location n singletons outside 3 standard deviations | 443 | 151 | 236 | 1.3 |
| Samples after final sample filters | 33,527 | 13,933 | 14,422 | 97.8 |
As a final step, we export common (allele frequency between 0.01 and 0.99) variants to plink format, prune, and evaluate final principal components for downstream analysis. The first six principal components are displayed below and coloured by case status.
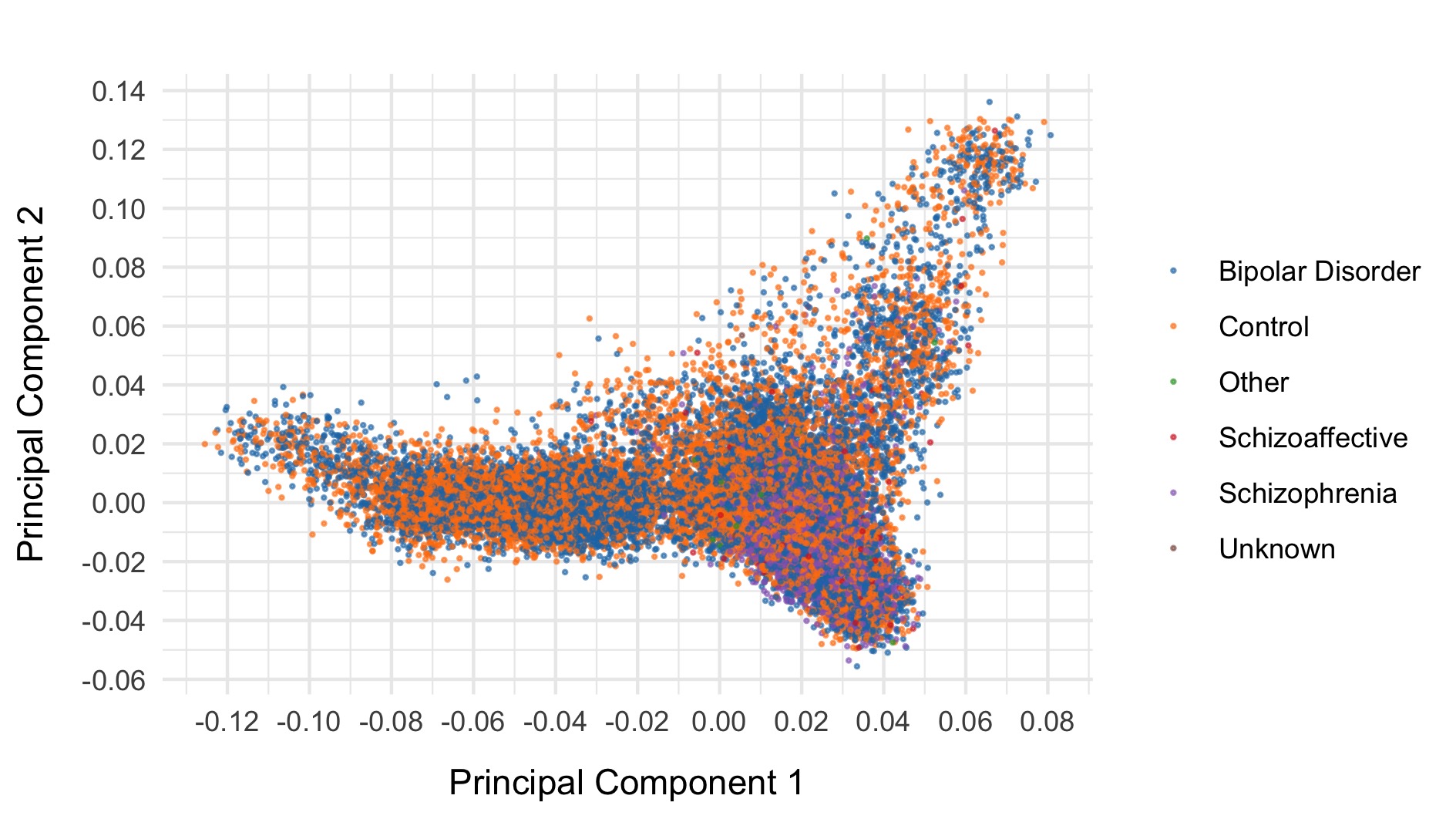
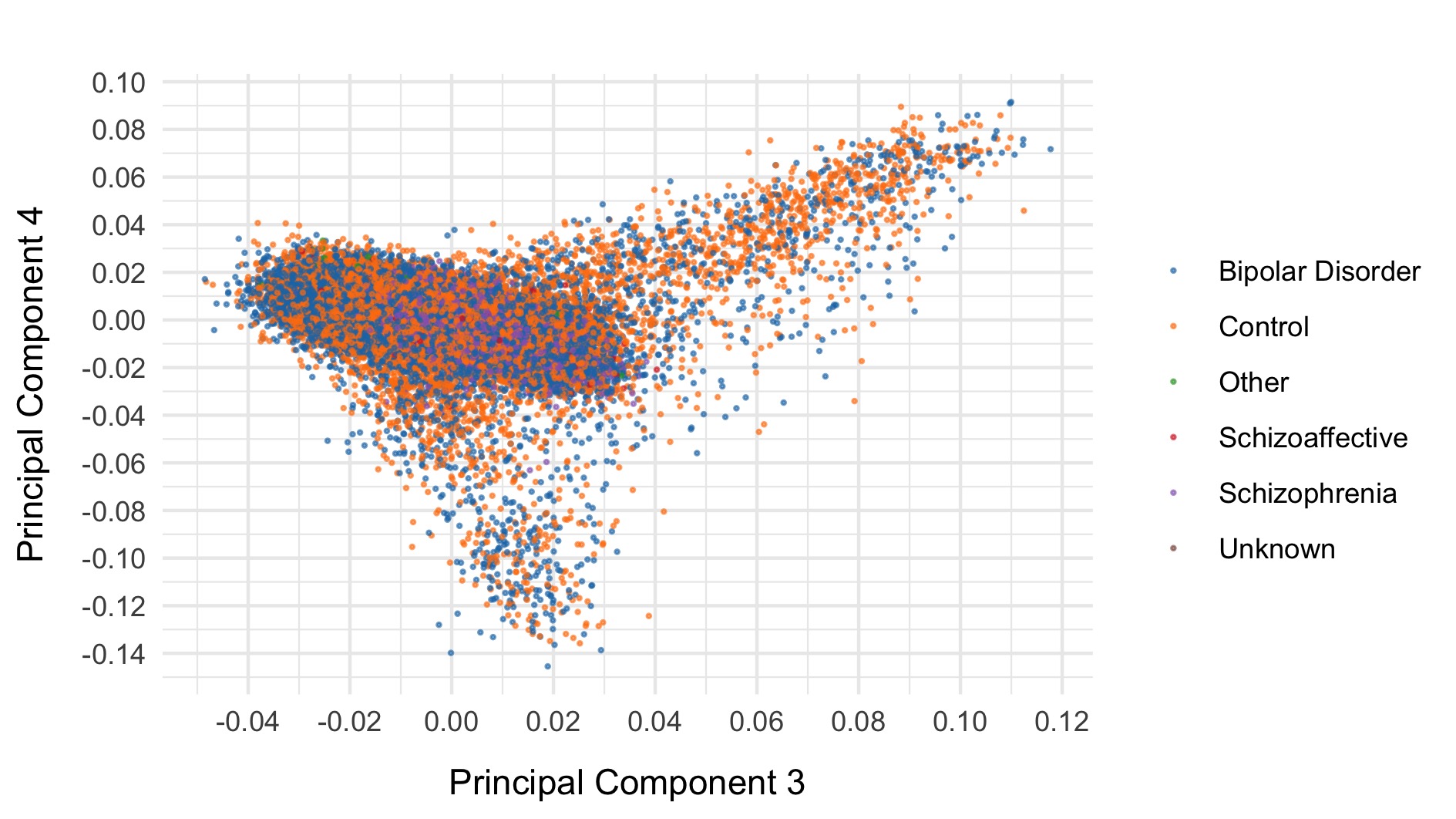
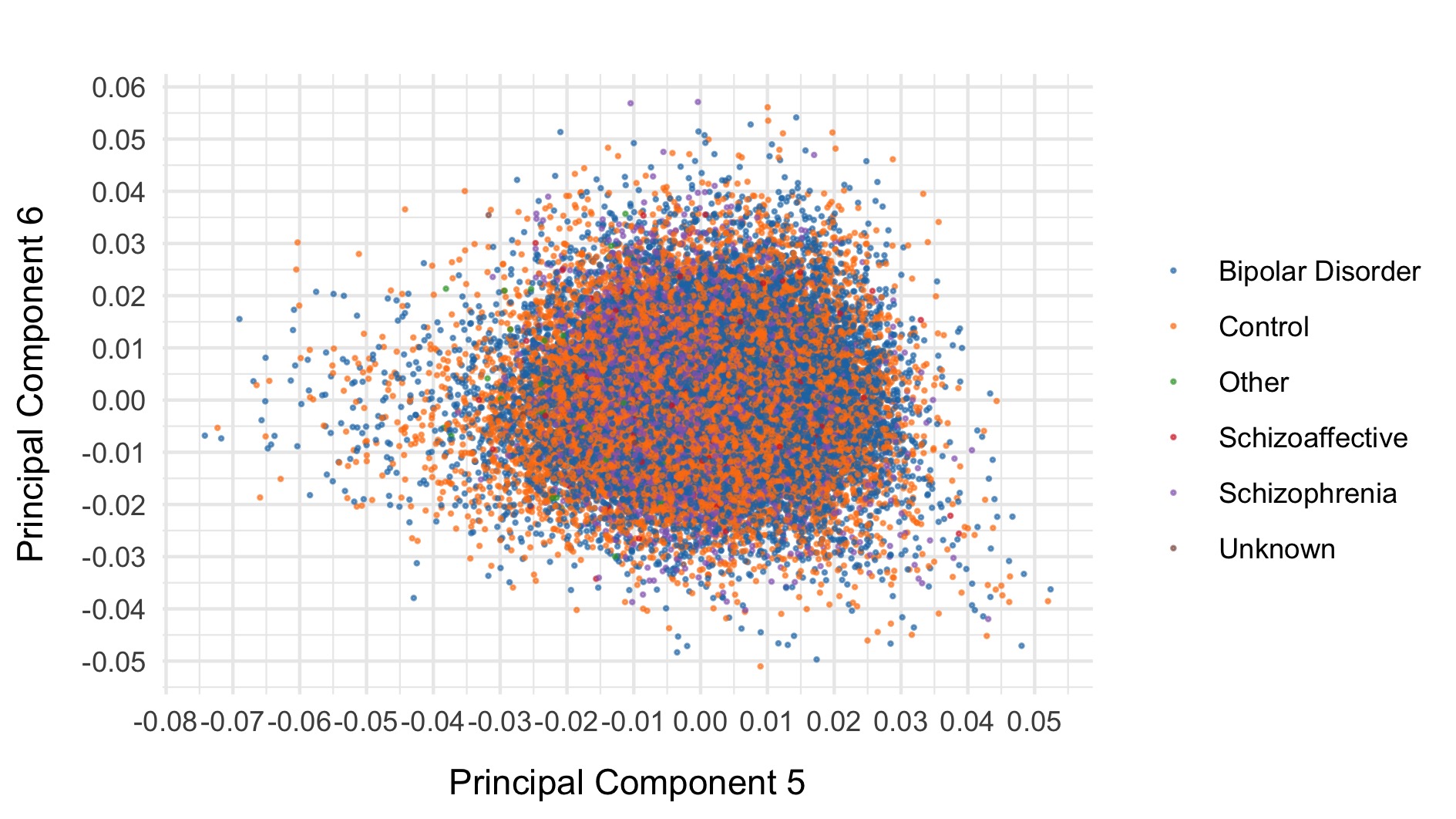
After all of this data cleaning, we save the resultant hail matrix tables for downstream analyses.
The resultant composition of the samples was as follows:
| Location | Bipolar Disorder | Schizoaffective | Schizophrenia | Other | Unknown | Controls | Total |
|---|---|---|---|---|---|---|---|
| Aberdeen, UK | 0 | 0 | 521 | 0 | 1 | 322 | 844 |
| Amsterdam, NED | 1,116 | 19 | 1 | 57 | 17 | 1,359 | 2,569 |
| Baltimore, USA | 267 | 0 | 0 | 4 | 0 | 41 | 312 |
| Boston, USA | 2,434 | 31 | 0 | 0 | 0 | 2,544 | 5,009 |
| Cambridge, UK | 0 | 0 | 0 | 0 | 0 | 2,656 | 2,656 |
| Cardiff, UK | 2,108 | 65 | 2,489 | 17 | 0 | 1,006 | 5,685 |
| Dublin, IRE | 150 | 11 | 27 | 2 | 0 | 7 | 197 |
| Edinburgh, UK | 711 | 6 | 271 | 0 | 0 | 58 | 1,046 |
| London, UK | 1,731 | 144 | 1,476 | 0 | 0 | 1,082 | 4,433 |
| Stockholm, SWE | 4,609 | 1 | 0 | 0 | 0 | 4,530 | 9,140 |
| Umea, SWE | 441 | 0 | 0 | 0 | 0 | 426 | 867 |
| Wurzburg, GER | 366 | 0 | 0 | 0 | 12 | 391 | 769 |
| Total | 13,933 | 277 | 4,785 | 80 | 30 | 14,422 | 33,527 |
The bipolar subtype information of the curated samples is:
| Location | Bipolar Disorder 1 | Bipolar Disorder 2 | Bipolar Disorder NOS | Schizoaffective | Bipolar Total (including schizoaffective) | Controls | Total |
|---|---|---|---|---|---|---|---|
| Aberdeen, UK | 0 | 0 | 0 | 0 | 0 | 322 | 322 |
| Amsterdam, NED | 951 | 155 | 9 | 19 | 1,135 | 1,359 | 2,494 |
| Baltimore, USA | 254 | 6 | 4 | 0 | 267 | 41 | 308 |
| Boston, USA | 1,503 | 279 | 404 | 31 | 2,465 | 2,544 | 5,009 |
| Cambridge, UK | 0 | 0 | 0 | 0 | 0 | 2,656 | 2,656 |
| Cardiff, UK | 1,301 | 681 | 62 | 65 | 2,173 | 1,006 | 3,179 |
| Dublin, IRE | 150 | 0 | 0 | 11 | 161 | 7 | 168 |
| Edinburgh, UK | 317 | 94 | 2 | 6 | 717 | 58 | 775 |
| London, UK | 1,169 | 350 | 0 | 144 | 1,875 | 1,082 | 2,957 |
| Stockholm, SWE | 2,095 | 1,595 | 791 | 1 | 4,610 | 4,530 | 9,140 |
| Umea, SWE | 297 | 141 | 3 | 0 | 441 | 426 | 867 |
| Wurzburg, GER | 201 | 145 | 13 | 0 | 366 | 391 | 757 |
| Total | 8,238 | 3,446 | 1,288 | 277 | 14,210 | 14,422 | 28,632 |
Taking a look at the breakdown of samples for which we have psychosis diagnosis information available:
| Location | Bipolar Disorder with Psychosis | Bipolar Disorder without Psychosis | Total |
|---|---|---|---|
| Boston, USA | 454 | 122 | 576 |
| Cardiff, UK | 993 | 693 | 1,686 |
| London, UK | 978 | 551 | 1,529 |
| Stockholm, SWE | 1,925 | 2,135 | 4,060 |
| Wurzburg, GER | 55 | 311 | 366 |
| Total | 4,405 | 3,812 | 8,217 |
Finally, we can look at the breakdown of samples in each of the age of onset categories:
Age at first impairment
| Location | Age First Impairment <12 | Age First Impairment 12-24 | Age First Impairment >24 | Total ‘24’ | Age First Impairment <18 | Age First Impairment 18-40 | Age First Impairment >40 | Total ‘40’ |
|---|---|---|---|---|---|---|---|---|
| Cardiff, UK | 61 | 709 | 352 | 1,122 | 401 | 671 | 50 | 1,122 |
| London, UK | 71 | 899 | 682 | 1,652 | 409 | 1,084 | 159 | 1,652 |
| Stockholm, SWE | 21 | 222 | 252 | 495 | 110 | 320 | 65 | 495 |
| Total | 153 | 1,830 | 1,286 | 3,269 | 920 | 2,075 | 274 | 3,269 |
Age at first symptoms
| Location | Age First Symptoms <12 | Age First Symptoms 12-24 | Age First Symptoms >24 | Total ‘24’ | Age First Symptoms <18 | Age First Symptoms 18-40 | Age First Symptoms >40 | Total ‘40’ |
|---|---|---|---|---|---|---|---|---|
| Cardiff, UK | 180 | 647 | 200 | 1,027 | 588 | 409 | 30 | 1,027 |
| Stockholm, SWE | 221 | 984 | 648 | 1,853 | 0 | 0 | 0 | 0 |
| Total | 401 | 1,631 | 848 | 2,880 | 588 | 409 | 30 | 1,027 |
Age at first diagnosis
| Location | Age First Diagnosis <12 | Age First Diagnosis 12-24 | Age First Diagnosis >24 | Total ‘24’ | Age First Diagnosis <18 | Age First Diagnosis 18-40 | Age First Diagnosis >40 | Total ‘40’ |
|---|---|---|---|---|---|---|---|---|
| Boston, USA | 0 | 0 | 0 | 0 | 156 | 152 | 57 | 365 |
| Stockholm, SWE | 45 | 755 | 882 | 1,682 | 345 | 1,093 | 244 | 1,682 |
| Total | 45 | 755 | 882 | 1,682 | 501 | 1,245 | 301 | 2,047 |